⚡ SoC 대역폭의 진짜 본질 — ‘넓은 통로’가 아니라 ‘교통 관제’다
SoC(System on Chip) 설계에서 가장 자주 과소평가되지만 시스템 성능의 상한을 사실상 결정하는 자원이 바로 대역폭(Bandwidth)이다. CPU·NPU·GPU가 동시에 데이터를 요구할 때 칩이 이를 어떻게 실어 나르느냐가 체감 성능을 가른다. 이 글은 대역폭의 정의와 계산법부터, 다수 IP가 경쟁하는 환경에서의 관리 메커니즘, 그리고 AI 시대에 인터커넥트가 NoC로 재편되는 흐름까지 한 번에 정리한다.
🧠 한 줄 요약 — 현대 SoC는 모든 IP의 요구 대역폭 총합보다 일부러 좁은 버스를 깐다. 핵심은 ‘얼마나 넓게’가 아니라 ‘폭주를 어떻게 관리하느냐’다.
📏 1. 대역폭이란 무엇인가 — 정의·단위·계산
대역폭은 특정 데이터 경로에서 단위 시간당 전송할 수 있는 데이터의 최대량이다. 칩 내부 데이터 파이프라인이 가진 물리적 ‘수송 능력’을 뜻한다. 통신 분야에서 말하는 ‘주파수 폭’과는 다른 개념으로, SoC에서는 데이터 처리량(throughput)에 가깝다.
▶ 단위 — Bps(Bytes per second). 최신 SoC는 GB/s, 칩렛·HBM 영역은 TB/s 단위를 쓴다.
대역폭 = 클럭 주파수(Hz) × 데이터 버스 폭(Byte) × 클럭당 전송 횟수(SDR=1 / DDR=2)
수식이 추상적이니 두 가지 실제 사례로 풀어 보자.
예시 ① 온칩 인터커넥트
1GHz, 256-bit(=32 Byte) 폭, SDR 버스 → 1×10⁹ × 32 × 1 = 32 GB/s
예시 ② 외부 메모리
64-bit(=8 Byte) LPDDR5X가 10,667 MT/s로 동작하면 → 8 × 10.667×10⁹ ≈ 85.3 GB/s. 이는 스냅드래곤 8 Elite·디멘시티 9400의 공시 피크 대역폭과 정확히 일치한다.
여기서 반드시 구분해야 할 것이 피크(이론) 대역폭과 유효(실효) 대역폭이다. 위 수식은 전부 피크값이다. 실제로는 메모리 리프레시·뱅크 충돌·버스 중재 지연·트랜잭션 단편화 때문에 피크의 60~80%만 실효로 쓰이는 경우가 흔하다. 설계자가 진짜 다뤄야 하는 숫자는 피크가 아니라 이 실효 대역폭이다.
약 60~80%
▷ 카탈로그의 화려한 피크값보다, 실전에서 손에 쥐는 70% 안팎이 설계 기준점이다.
👀 2. 대역폭을 바라보는 두 가지 시선
같은 ‘대역폭’이라도 누구의 관점이냐에 따라 의미가 정반대다. 이 시각차를 이해하는 것이 시스템 아키텍처의 출발점이다.
| 관점 | 성격 | 의미 · 비유 |
|---|---|---|
| 🔧 IP 설계자 | 수요(Demand) | 코어가 목표 성능(FPS·TOPS)을 내기 위해 요구하는 데이터량 · “차량 통행 수요” |
| 🛣️ 버스 설계자 | 공급(Capacity) | 모든 트래픽을 병목 없이 메모리까지 실어 나르는 수송 능력 · “고속도로 차선 수·제한속도” |
IP 설계자는 “내 NPU가 굶지 않으려면 초당 몇 GB가 필요한가”를 묻고, 버스 설계자는 “이 모든 IP의 요청을 어떤 우선순위로 어디까지 수용할 것인가”를 묻는다. 이 둘 사이의 간극을 메우는 일이 곧 인터커넥트 설계다.
🎯 3. ‘초과 할당’은 버그가 아니라 설계 의도다
흔히 “각 IP가 요구하는 대역폭의 총합이 버스 용량보다 크면 잘못 설계된 것”이라고 직관하기 쉽다. 그러나 실제 SoC는 의도적으로 그렇게 설계된다. 이를 초과 할당(Over-subscription)이라 부른다. 아래 도식은 CPU·GPU·NPU의 순간 요구 합(95 GB/s)이 인터커넥트 수용 능력(60 GB/s)을 넘어서는 구조를 보여 준다.
direction: right
CPU: "CPU\n순간 요구: 15 GB/s" {
style: { fill: "#e0f7fa"; stroke: "#006064" }
}
GPU: "GPU\n순간 요구: 40 GB/s" {
style: { fill: "#fff9c4"; stroke: "#fbc02d" }
}
NPU: "NPU\n순간 요구: 40 GB/s" {
style: { fill: "#ffe0b2"; stroke: "#e65100" }
}
Interconnect: "System Interconnect\n수용 능력: 60 GB/s\n(Over-subscribed)" {
shape: cylinder
style: { fill: "#f5f5f5"; stroke: "#9e9e9e"; stroke-width: 2 }
}
Memory: "Memory Controller\n병목 발생 구간" {
shape: database
style: { fill: "#e8eaf6"; stroke: "#283593" }
}
CPU -> Interconnect
GPU -> Interconnect
NPU -> Interconnect
Interconnect -> Memory: "총 95 GB/s 요청 유입 시\n체증(Congestion)"
🔗 다이어그램 요약: CPU·GPU·NPU가 동시에 던지는 순간 요구(15+40+40=95 GB/s)가 인터커넥트 수용 능력(60 GB/s)을 넘는다 — 이렇게 일부러 좁게 깔아두고, 메모리 컨트롤러 앞에서 생기는 체증은 별도 기법으로 흡수한다.
왜 일부러 좁게 설계하는가 — 통계적 다중화(Statistical Multiplexing). 시스템 내 모든 IP가 동시에 100% 피크 트래픽을 쏟아내는 최악의 상황은 현실에서 극히 드물다. 트래픽은 버스트(burst)로 발생하고 시간적으로 흩어진다. 희박한 동시-피크에 대비해 모든 IP의 요구량을 1:1로 다 깔면 배선 면적과 전력이 비경제적으로 폭증한다. 그래서 평균적 동시 수요에 맞춰 버스를 좁게 잡고, 순간 폭주는 다른 기법으로 흡수한다.
그렇다면 정말 동시에 깨어나면? 고성능 IP들이 한꺼번에 대량 요청을 던지면 버스 용량을 초과하는 체증이 발생한다.
🔴 지연(Latency) 폭증 — 요청 패킷이 내부 큐에 적체되며 응답 시간이 늘고, CPU의 캐시 미스 페널티가 극대화된다.
🔴 언더플로우·시스템 정지 — 디스플레이 컨트롤러처럼 정해진 시간 안에 반드시 데이터를 받아야 하는 실시간 IP가 굶으면 화면 깜빡임·끊김, 심하면 시스템 행(hang)으로 이어진다.
🔁 4. 병목을 다루는 두 갈래 — ‘관리’와 ‘확장’
초과 할당 구조의 부작용은 크게 두 방향으로 통제한다. 트래픽을 똑똑하게 관리하거나, 버스 용량 자체를 확장하는 것이다.
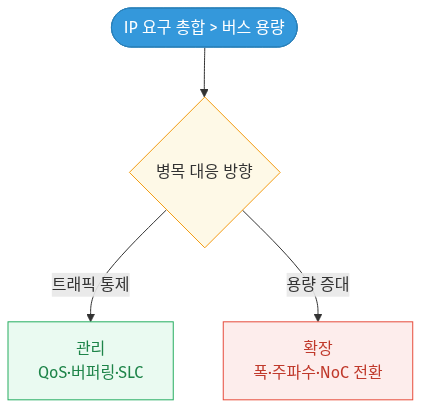
🔁 다이어그램 요약: IP 요구 총합이 버스 용량을 넘으면 두 길로 갈린다 — 트래픽을 통제하는 ‘관리'(QoS·버퍼링·SLC)와 용량 자체를 키우는 ‘확장'(버스 폭·주파수·NoC 전환).
(A) 관리 — 트래픽을 통제한다
🟢 QoS 기반 중재(Arbitration) — 인터커넥트가 요청의 중요도를 판별해 통행 우선순위를 차등 부여한다. 지연에 민감한 CPU·디스플레이 트래픽은 최우선, 처리량만 채우면 되는 GPU 백그라운드 연산·DMA 복사는 후순위로 미룬다.
🟢 버퍼링 · SLC — IP와 인터커넥트 사이에 대용량 SRAM 버퍼나 시스템 레벨 캐시(System Level Cache)를 두어 순간 버스트를 흡수하고, 외부 메모리 접근 빈도 자체를 줄인다.
(B) 확장 — 인터커넥트의 절대 대역폭을 늘린다
“버스 대역폭을 늘린다”는 건 앞의 수식 중 두 변수 하나를 키운다는 뜻이며, 각각 뚜렷한 대가가 따른다.
🟡 데이터 버스 폭 확장(Width) — 128-bit → 256-bit. 한 번에 더 많은 데이터를 보내지만, 칩 내부에 수천 가닥의 금속 배선을 추가해야 하므로 배선 혼잡도(routing congestion)와 다이 면적이 급증한다.
🟡 클럭 주파수 증가(Frequency) — 1GHz → 2GHz. 처리는 빨라지지만 동적 전력이 주파수에 비례해 오르고, 짧아진 클럭 주기 안에 신호를 도달시키는 타이밍 클로저(timing closure)가 극도로 까다로워진다.
두 방법 모두 단일 버스 안에서는 PPA(Power·Performance·Area) 한계에 부딪힌다. 바로 여기서 토폴로지 자체를 바꾸는 세 번째 길, NoC가 등장한다.
📊 5. 외부 메모리 대역폭은 지금 어디까지 왔나
설계 마진을 가늠하려면 버스가 최종적으로 향하는 외부 메모리 대역폭의 현재 수준을 알아야 한다. 아래는 2024~2025 플래그십 기준 피크 대역폭이다(퀄컴·미디어텍·애플 공식 스펙).
모바일 SoC의 외부 대역폭이 60~85 GB/s에 머무는 반면, 고성능 GPU·NPU는 단독으로도 수십~수백 GB/s의 버스트를 유발한다. 애플이 M4 Max에서 채널 폭을 키워 500 GB/s대를 확보한 것은 온디바이스 AI·고해상도 그래픽의 데이터 수요가 일반 메모리 버스로는 감당이 안 된다는 방증이다. “고성능 IP가 늘수록 버스 마진이 더 필요하다”는 직관은 이렇게 데이터로 뒷받침된다.
🕸️ 6. 레거시 버스에서 NoC로 — 인터커넥트의 재편
전통적 버스(AMBA AHB/AXI 기반 Crossbar Switch)는 마스터(IP)와 슬레이브(메모리) 사이에 전용 경로를 까는 방식이다. IP 개수 N이 늘면 배선 복잡도가 O(N²)로 폭증해 확장이 막힌다. NoC(Network on Chip)는 이를 인터넷처럼 패킷 라우팅으로 대체한다.
direction: right
classes: {
core: { shape: rectangle; style: { fill: "#e3f2fd"; stroke: "#1565c0" } }
router: { shape: rectangle; style: { fill: "#e8f5e9"; stroke: "#2e7d32"; font-weight: bold } }
}
Legacy: "Legacy Crossbar\n(배선 복잡도 O(N^2))" {
style.fill: transparent
M1: IP1 {class: core}; M2: IP2 {class: core}; M3: IP3 {class: core}
S1: Mem1 {class: core}; S2: Mem2 {class: core}; S3: Mem3 {class: core}
M1 -> S1; M1 -> S2; M1 -> S3
M2 -> S1; M2 -> S2; M2 -> S3
M3 -> S1; M3 -> S2; M3 -> S3
}
NoC: "NoC Mesh\n(패킷 라우팅·선형 확장)" {
style.fill: transparent
R11: Router {class: router}; R12: Router {class: router}
R21: Router {class: router}; R22: Router {class: router}
IP1: CPU {class: core}; IP2: GPU {class: core}
IP3: NPU {class: core}; IP4: DMA {class: core}
IP1 <-> R11; IP2 <-> R12; IP3 <-> R21; IP4 <-> R22
R11 <-> R12: "우회 경로"; R11 <-> R21; R12 <-> R22; R21 <-> R22
}
🔗 다이어그램 요약: 왼쪽 Crossbar는 모든 IP↔메모리를 전용선으로 다 잇느라 배선이 IP 수의 제곱으로 폭증한다. 오른쪽 NoC는 라우터 그물망에 IP를 붙이고 패킷을 우회시켜, IP가 늘어도 배선이 선형으로만 증가한다.
레거시와 다른 NoC의 네 가지 특징
✓ 확장성 (O(N²) → 선형) — Crossbar는 IP 추가 시 배선이 제곱으로 늘지만, NoC는 라우터를 Mesh·Ring 토폴로지로 배치해 선형 복잡도만 요구한다.
✓ Bisection Bandwidth 향상 — 칩을 반으로 갈랐을 때 통과하는 최대 대역폭이 NoC에서 더 높다. 한 경로에 트래픽이 몰리면 라우터가 우회 경로로 분산시켜, NPU·GPU의 광대역 병렬 트래픽에 유리하다.
✓ GALS 구조 — 대형 SoC는 단일 클럭으로 전체 타이밍을 맞추기 불가능하다. NoC는 각 IP가 자기 클럭으로 동작하고(Globally Asynchronous, Locally Synchronous) 네트워크 인터페이스로만 비동기 통신하게 해준다.
✓ 칩렛(Chiplet)으로의 확장 — NoC 개념이 단일 다이를 넘어 패키지로 확장 중이다. UCIe 같은 die-to-die 표준이 NoC를 패키징 영역까지 잇는다.
핵심 보정 — ‘카탈로그 대역폭’은 존재하지 않는다
상용 NoC IP는 고정 스펙이 아니라 설계자가 구성하는 가변 IP다. 여기서 견해가 갈리는 게 아니라, 주요 공급사 모두가 같은 말을 한다.
Arm (CMN-700 / CMN S3) — 고도로 구성 가능한 인터커넥트로, 단일 고정 bisection 대역폭 값이 없다. 최대 12×12 Mesh, 2.5GHz+, 데이터 경로 폭(Single/Dual) 등 설계자의 선택으로 총 대역폭이 결정된다.
Arteris · Synopsys — 대역폭과 성능은 설계의 토폴로지·데이터 폭·클럭 주파수에 따라 스케일링된다. 즉 NoC 대역폭은 고정된 하드웨어 값이 아니라 구성 가능한 성능 지표이며, 툴(Socrates, Platform Architect)이 트래픽 요구에 맞춰 생성한다.
칩렛 · UCIe — TB/s 시대
2024년 8월 공개된 UCIe 2.0은 레인당 속도를 32 GT/s로 1.1과 동일하게 유지하면서 시스템 아키텍처·3D 패키징 호환에 초점을 맞췄다(속도 점프는 차세대로 이연). 대역폭은 패키징 방식에 좌우되며, Advanced Packaging(실리콘 인터포저·EMIB)에서는 약 20 Tbps/mm(≈2.5 TB/s per mm) 이상의 밀도를 달성해, 다이 엣지당 5~10 TB/s 이상을 확보한다. 모바일 메모리 버스(85 GB/s)와 비교하면 두 자릿수 배 이상의 차이다.
🧭 7. 결론 — 대역폭은 ‘넓이’가 아니라 ‘관리’다
🟢 대역폭은 ‘넓이’가 아니라 ‘관리’의 문제다. 현대 SoC는 IP 요구 총합이 버스 용량을 초과하도록(over-subscription) 의도적으로 설계하고, 통계적 다중화 위에서 QoS 중재·버퍼링으로 순간 폭주를 흡수한다. 마진을 무작정 키우는 것이 답이 아니라, 어떤 트래픽을 언제 양보시킬지를 설계하는 것이 핵심이다.
🟢 NPU·GPU의 부상이 토폴로지 전환을 강제했다. 데이터 수요가 단일 Crossbar의 PPA 한계를 넘어서면서, 폭·주파수 확장만으로는 한계에 부딪혔고 NoC로의 전환은 선택이 아닌 필연이 되었다.
🟢 ‘대역폭 스펙’은 고정값이 아니다. Arm·Arteris·Synopsys 모두 NoC를 가변 구성 IP로 제공한다. 설계자의 일은 카탈로그에서 숫자를 고르는 것이 아니라, 트래픽 프로파일을 분석해 토폴로지·폭·클럭·QoS를 합성(generate) 하는 것이다.
🟢 다음 전선은 패키지다. 단일 다이의 NoC가 칩렛 경계를 넘어 UCIe로 확장되며, 시스템 대역폭의 무대는 온칩(GB/s)에서 다이-투-다이(TB/s)로 이동하고 있다.
결국 현대 SoC의 대역폭은 ‘넓은 통로’를 넘어, 패킷 우선순위를 판별하고 병목을 자율 회피하는 지능형 교통망 통제 아키텍처로 진화했다. NoC의 구조적 효율과 칩렛 확장이 향후 시스템 경쟁력을 가르는 핵심 척도가 될 것이다.
📚 참고: 퀄컴·미디어텍·애플 공식 칩셋 스펙, Arm(CMN-700/CMN S3)·Arteris(FlexNoC/Ncore)·Synopsys NoC 기술 문서, UCIe 2.0 사양.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-18