클럭 게이팅의 심장, ICG 표준 셀: 왜 플립플롭이 아니라 래치인가
스마트폰 AP부터 AI 가속기까지, 칩의 발열과 배터리 수명을 좌우하는 가장 조용한 부품이 바로 ICG(Integrated Clock Gating) 표준 셀이다. 흥미로운 점은 이 셀의 핵심에 플립플롭이 아니라 한 단계 더 단순해 보이는 ‘래치(latch)’가 들어간다는 것이다. 왜 더 단순한 소자를 일부러 골랐을까. 그 이유 안에 고속 디지털 설계의 타이밍과 전력에 대한 가장 우아한 트레이드오프가 압축돼 있다.
1. 왜 클럭이 전력의 주범인가
모든 동기식(synchronous) 디지털 회로는 클럭(clock)에 맞춰 동작한다. 클럭은 칩 전체를 가로지르며 1초에 수억~수십억 번(수 GHz) 0과 1을 반복하는 신호다. 문제는 이 신호가 연산이 필요 없는 순간에도 멈추지 않는다는 데 있다.
반도체의 동적 전력(dynamic power)은 잘 알려진 관계 P ∝ α·C·V²·f를 따른다. 여기서 f(스위칭 주파수)와 α(스위칭 활동률)가 핵심이다. 클럭망(clock tree)과 그 끝단의 플립플롭(flip-flop)은 데이터가 바뀌든 안 바뀌든 매 주기 토글하므로 활동률이 사실상 100%에 가깝다. 그 결과 업계·학계 추정치 기준으로 칩 전체 동적 전력의 상당 부분이 순수하게 클럭 분배망에서 소비된다.
30~40% (흔히 인용)
클럭 게이팅(clock gating)은 쉬고 있는 로직 블록으로 가는 클럭을 끊어, 그 블록의 플립플롭 스위칭(그리고 클럭 버퍼 토글)을 멈춰 전력을 차단하는 기법이다. 보고된 절감 폭은 워크로드·블록 성격에 따라 편차가 크지만, 실제 사례를 모으면 다음과 같다.
📊 위 수치는 각각 인터페이스 IP(eMMC)의 컨텍스트 인지 게이팅, Synopsys Power Compiler의 자동 데이터패스 게이팅, data-flow IP의 조합 단계 게이팅, ARM 계열 8-issue 코어의 결정적 클럭 게이팅(DCG, 전체 프로세서 전력 기준) 사례다.
⚠️ 수치 주의: 위 값들은 모두 특정 설계·워크로드에서의 보고 사례다. “ICG를 넣으면 항상 X% 절감”으로 일반화할 수 없으며, 블록의 유휴 비율(idle ratio)에 비례한다고 보는 것이 정확하다.
2. 직관적인 ‘AND 게이트’ 해법이 실패하는 이유
클럭을 끊는 가장 단순한 발상은 클럭과 enable을 AND로 묶는 것이다(GCLK = CLK & EN). 그러나 이 방식에는 치명적 결함이 있다.
🔴 글리치(glitch) 문제. Enable 신호가 클럭이 High인 도중에 값이 바뀌면, 출력에 불완전한 펄스 조각(runt pulse)이 튀어나온다. 이 짧은 펄스가 하위 플립플롭에 도달하면 의도치 않은 캡처가 일어나 회로 상태가 깨진다(셋업/홀드 위반과 동등한 효과). 즉, 단순 AND로는 “Enable은 클럭이 활성 엣지에 도달하는 순간 절대 흔들리면 안 된다”는 제약을 보장할 수 없다.
“By placing a negative-level sensitive latch before the AND gate, the enable signal is synchronized… ensuring the output clock pulse is either fully enabled or fully disabled, preventing partial or ‘runt’ pulses.” — AnySilicon, Clock Gating Explained
3. 왜 플립플롭이 아니라 래치인가 — 핵심 논점
글리치를 막으려면 Enable을 클럭에 동기화해야 한다. 여기서 두 가지 선택지가 갈린다.
3.1 하강 엣지 플립플롭(negedge FF)의 함정
글리치 차단을 위해 하강 엣지 FF로 Enable을 잡는 방법이 떠오른다. 그러나 두 가지 벽에 부딪힌다.
① 반 주기(half-cycle) 타이밍 압박. 데이터 로직은 보통 상승 엣지에서 출발한다. Enable을 만드는 조합 로직이 하강 엣지 FF에 잡히려면, 그 계산이 같은 주기의 하강 엣지 이전에 끝나야 한다 — 즉 가용 시간이 반 주기로 줄어든다. 수 GHz 설계에서 이 조건은 거의 불가능에 가깝다.
② 면적·전력 비효율. Master-Slave 구조의 FF는 보통 20개 이상의 트랜지스터를 쓴다. 클럭 트리에 수십만~수백만 개씩 들어갈 셀로는 무겁다.
3.2 negative-level 래치(transparent-low)의 우아함
표준 ICG는 클럭이 Low일 때 투명(transparent)해지는 negative-level sensitive latch를 쓴다. 이것이 위 문제를 한 번에 해결한다.
🟢 시간 차용(time borrowing). 래치는 클럭이 Low인 구간 전체 동안 Enable을 통과시킨다. 따라서 조합 로직은 다음 상승 엣지 직전까지만 값을 확정하면 되어, 사실상 한 주기에 가까운 타이밍 여유를 확보한다. 타이밍 클로저가 압도적으로 유리해진다.
🟢 글리치 차단. 클럭이 High로 올라가는 순간 래치는 직전 값을 잠그고(hold) 유지한다. High 구간 동안 Enable이 요동쳐도 출력은 미동도 않으므로, AND를 거친 GCLK는 항상 “온전한 펄스 또는 펄스 없음” 둘 중 하나가 된다.
🟢 가벼움. 래치는 FF보다 트랜지스터 수가 적어 면적과 삽입 지연이 작다.
두 선택지를 나란히 놓으면 차이가 분명하다.
| 항목 | 하강 엣지 FF | negative-level 래치 |
|---|---|---|
| enable 계산 여유 | 반 주기 (압박 심함) | 거의 한 주기 (time borrowing) |
| 글리치 차단 | 가능 | 가능 (High 구간 hold) |
| 트랜지스터 수 | 20개+ (무거움) | 적음 (가벼움) |
| 고속 설계 적합성 | 어려움 | 우수 |
4. 구조와 코드, 그리고 파형
4.1 ICG 셀 내부 구조 (OR → Latch → AND)
DFT(Design For Test)를 위한 TE(Test Enable)를 Enable과 OR로 병합한 뒤, negative-level 래치를 거쳐 AND로 클럭에 다시 곱한다.
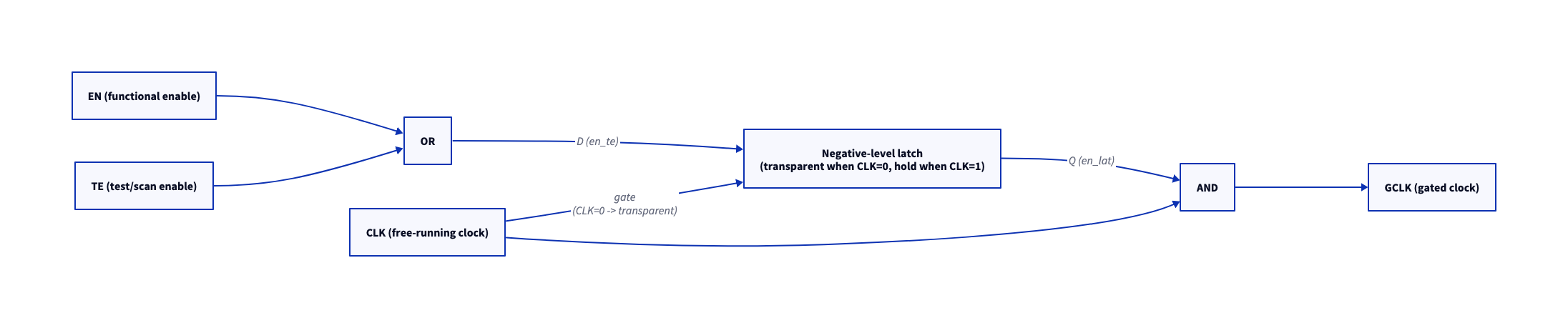
🔗 다이어그램 요약: 기능 enable(EN)과 테스트 enable(TE)을 OR로 합친 신호가 negative-level 래치의 입력(D)으로 들어가고, 래치는 클럭이 Low일 때만 이 값을 통과시킨다. 래치 출력(Q)을 다시 클럭과 AND하면 글리치 없는 게이팅 클럭(GCLK)이 나온다.
TSMC 표준 셀 라이브러리에서 이 셀의 대표 이름이 CKLNQ다(게이팅 클럭 래치, Negative-level, Q output only). 뒤의 숫자(CKLNQD1/D2/D4)는 클럭 트리 부하를 감당하는 구동 강도(drive strength)를 뜻한다.
4.2 게이트 인스턴스 형태의 Verilog
프리미티브 게이트(or/and)를 인스턴스화하고, 래치만 레벨 민감 동작으로 모델링한 구조다. (Verilog에는 레벨 민감 래치 프리미티브가 없어 래치는 라이브러리 셀 또는 거동 모델로 표현한다.)
// 표준 ICG (CKLNQ 계열) 게이트-인스턴스 구조
module icg_cell (
input wire CLK, // 자유 발진 클럭
input wire EN, // 기능 enable
input wire TE, // 테스트/스캔 enable
output wire GCLK // 게이팅된 클럭
);
wire en_te; // EN | TE
reg en_lat; // 래치 출력
// 1) 기능 enable과 테스트 enable 병합 (OR 게이트 인스턴스)
or u_or (en_te, EN, TE);
// 2) negative-level 래치: CLK==0 동안 투명, CLK==1 동안 hold
always @* if (!CLK) en_lat = en_te;
// 3) 래치된 enable을 클럭에 다시 곱함 (AND 게이트 인스턴스)
and u_and (GCLK, CLK, en_lat);
endmodule4.3 동작 파형 (transparent/hold)
아래 파형은 두 가지 악조건을 의도적으로 넣었다 — ① Enable이 클럭 High 도중 상승하는 경우, ② Enable이 클럭 Low 구간에서 글리치하는 경우. (논의 단순화를 위해 TE=0으로 고정, 즉 en_te = EN.)
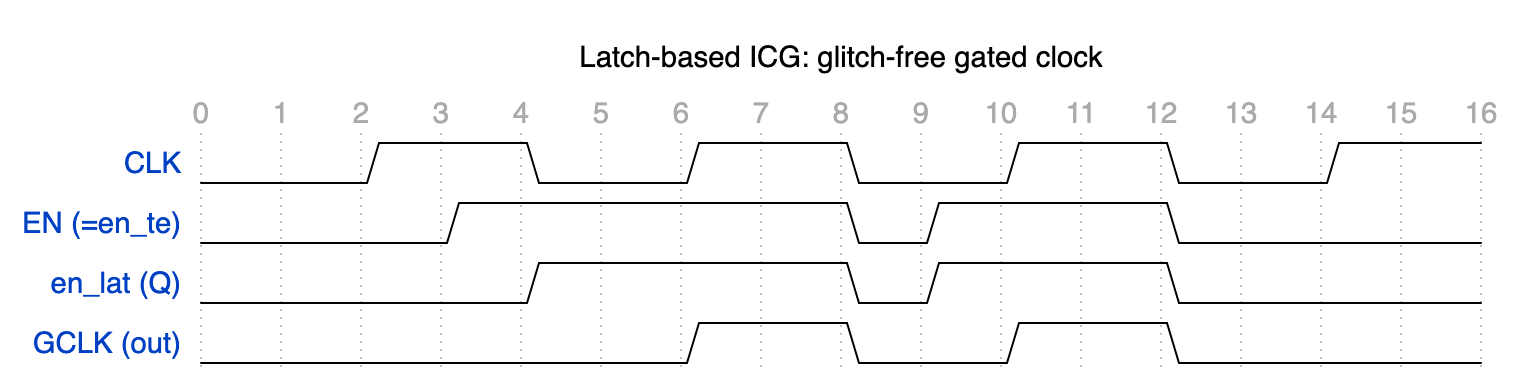
📊 다이어그램 요약: 클럭 High 도중 EN이 올라가도 래치가 hold 상태라 GCLK는 미동도 없고(runt pulse 없음), 클럭 Low 구간에서 EN이 글리치쳐도 AND가 막아 GCLK는 0을 유지한다. 결국 GCLK에는 온전한 펄스만 통과한다.
파형 해설 (본문과 일치):
▶ t=3 (CLK High): EN이 클럭 High 도중 0→1로 상승한다. 그러나 래치는 High 구간에서 hold이므로 en_lat는 0을 그대로 유지한다 — 단순 AND였다면 여기서 runt pulse가 났겠지만, GCLK는 미동도 없다.
▶ t=4 (CLK Low): 클럭이 Low로 내려가 래치가 transparent해지고, 대기하던 EN=1이 en_lat로 통과한다. 이때 CLK=0이라 GCLK는 안전하게 0.
▶ t=6~7 (CLK High): 미리 준비된 en_lat=1을 바탕으로 온전하고 깨끗한 GCLK 펄스 하나가 생성된다.
▶ t=8~9 (CLK Low): EN에 1→0→1 글리치가 발생한다. 래치는 투명하므로 en_lat도 이 변화를 그대로 따라 요동친다(0 후 1). 그러나 CLK=0이라 AND 출력 GCLK는 0으로 무해하게 걸러진다.
▶ t=10~11: 다시 깨끗한 GCLK 펄스. t=12 이후 EN이 Low 구간에서 0으로 내려가 래치가 0을 캡처하고, t=14~15에서 GCLK는 정상적으로 차단된다.
🧠 핵심은 High 구간에서는 hold(글리치 무시), Low 구간에서는 transparent(D를 즉시 추종)라는 레벨 민감 거동 자체가 글리치 차단과 시간 차용을 동시에 달성한다는 점이다.
5. 가장 중요한 질문 — 왜 ‘별도의 표준 셀’이어야 하는가
논리만 보면 OR+래치+AND의 단순 결합이다. 그런데도 설계자가 이를 직접 조립하지 않고 파운드리(TSMC, 삼성 등)가 제공하는 전용 표준 셀(CKLNQ 등)을 반드시 인스턴스화하는 데에는 분명한 엔지니어링적 이유가 있다. 이 점이 ICG가 별도로 존재하는 핵심이다.
① CTS(Clock Tree Synthesis)가 ‘클럭 노드’로 인식하게 하려고. 클럭은 칩 전역 플립플롭에 수 ps 오차 내로 도달해야 한다(skew 관리). 설계자가 래치·AND를 흩어 놓으면 합성 툴은 이를 평범한 데이터 패스로 취급해 클럭 트리 밸런싱이 망가진다. 전용 ICG 셀로 지정해야 툴이 이를 ‘클럭 트리 상의 특별한 노드’로 보고 skew를 정밀하게 맞춘다.
② SPICE 레벨 특성화(characterization)가 끝나 있다. 클럭은 미세한 지연·왜곡만으로도 칩을 먹통으로 만든다. 표준 ICG 셀은 내부 래치와 AND 사이의 배선·트랜지스터 사이징이 파운드리에 의해 검증되어, 내부 레이스 컨디션 걱정이 없다.
③ DFT가 하드웨어로 내장돼 있다. 스캔 테스트/ATPG 모드에서는 클럭이 계속 토글해야 한다. ICG가 클럭을 끊으면 스캔 체인이 끊겨 fault coverage가 급락한다. 표준 셀의 TE 핀을 1로 강제하면 기능 enable과 무관하게 클럭이 무조건 통과(override)하도록 설계돼 있다.
6. 그늘 — ICG가 부르는 백엔드·검증 비용
전력 이득은 공짜가 아니다. 같은 자료들이 다음 부작용을 함께 지적한다.
▶ Insertion delay & skew: ICG 자체 지연이 클럭 트리에 더해져, ICG를 거친 FF와 거치지 않은 FF 사이에 skew가 생긴다. 이를 맞추려 CTS에서 버퍼를 다수 추가해야 한다.
▶ OCV 페시미즘: ICG는 클럭 트리에 ‘uncommon path’를 만든다. 루트에 가까울수록 PVT 변동 분석에서 더 큰 비관성을 적용해야 해 STA의 타이밍 클로저가 어려워진다.
▶ X-propagation: RTL/게이트 시뮬레이션에서 Enable이 미초기화 X이면 ICG가 그 X를 하위 클럭 핀으로 전파해, 실제 하드웨어와 무관하게 하위 레지스터를 X로 오염시켜 시뮬레이션이 깨질 수 있다.
▶ 테스트성 저하: 위 5절 DFT 이슈의 이면 — TE 우회 설계를 빠뜨리면 ATPG 커버리지가 무너진다.
7. 결론 — 단순한 논리를 셀로 봉인하는 이유
표준 ICG 셀은 단순 전력 절감 트릭이 아니라 현대 SoC·ASIC의 필수 인프라다. 모바일 AP부터 AI 가속기까지 발열 제어와 배터리 수명을 위해 수십만~수백만 개가 삽입된다.
이 기법의 묘미는 “왜 플립플롭이 아니라 래치인가”에 응축돼 있다 — 고속 설계에서 치명적인 반 주기 타이밍 압박을 래치의 time borrowing으로 풀면서, 동시에 hold 거동으로 glitch-free를 보장하는 우아한 해법이기 때문이다. 그리고 이 단순한 논리를 굳이 전용 표준 셀로 봉인하는 이유는, 클럭이라는 신호가 CTS·STA·DFT 전 영역에서 특별 취급을 받아야만 칩이 정상 동작하기 때문이다.
🧠 절감 수치(35~75% 등)는 인상적이지만 블록의 유휴 비율에 비례하는 값이며, insertion delay·OCV·X-propagation이라는 백엔드 비용과 항상 함께 고려되어야 한다. ICG는 “전력을 거저 줄여 주는 마법”이 아니라, 타이밍·테스트·검증의 비용을 감수하고 얻는 잘 설계된 거래다.
본 글은 디지털 SoC 설계의 클럭 게이팅 개념을 이해하기 위한 정보성 콘텐츠입니다. 인용된 절감 수치는 특정 설계·워크로드의 보고 사례이며, 실제 설계 결과는 공정·라이브러리·워크로드에 따라 달라질 수 있습니다.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-17