사이버 보안 특화 AI 모델 경쟁 — OpenAI GPT-5.5-Cyber와 Anthropic Mythos·Fable 5
프런티어 AI의 무게중심이 ‘대화’에서 ‘사이버 방어’로 이동한 2026년 6월의 발표를 1차 자료 기준으로 정리합니다.
2026년 6월, 프런티어 AI 경쟁의 핵심 무대가 일상 대화 능력에서 사이버 방어로 옮겨갔다. OpenAI는 ‘Daybreak’ 플랫폼과 함께 GPT-5.5-Cyber 정식판을, Anthropic은 ‘Project Glasswing’과 함께 Mythos 5·Fable 5를 연이어 내놓았다. 두 진영의 목표는 같다 — 방대한 코드베이스에서 취약점을 자율적으로 찾아내고 검증·패치하는 보안 에이전트다. 그러나 성능 수치와 배포 정책에서 뚜렷이 갈렸고, 여기에 미국 정부의 수출통제 개입이라는 전례 없는 변수까지 끼어들었다.
무엇이 발표됐나 — Daybreak와 Glasswing
먼저 이름이 비슷해 헷갈리기 쉬운 모델들을 분리해야 한다. 같은 베이스 모델이라도 배포 구성(deployment configuration)에 따라 능력과 공개 범위가 완전히 달라지기 때문이다. 아래 도식이 두 회사의 모델 계보를 한눈에 보여준다.
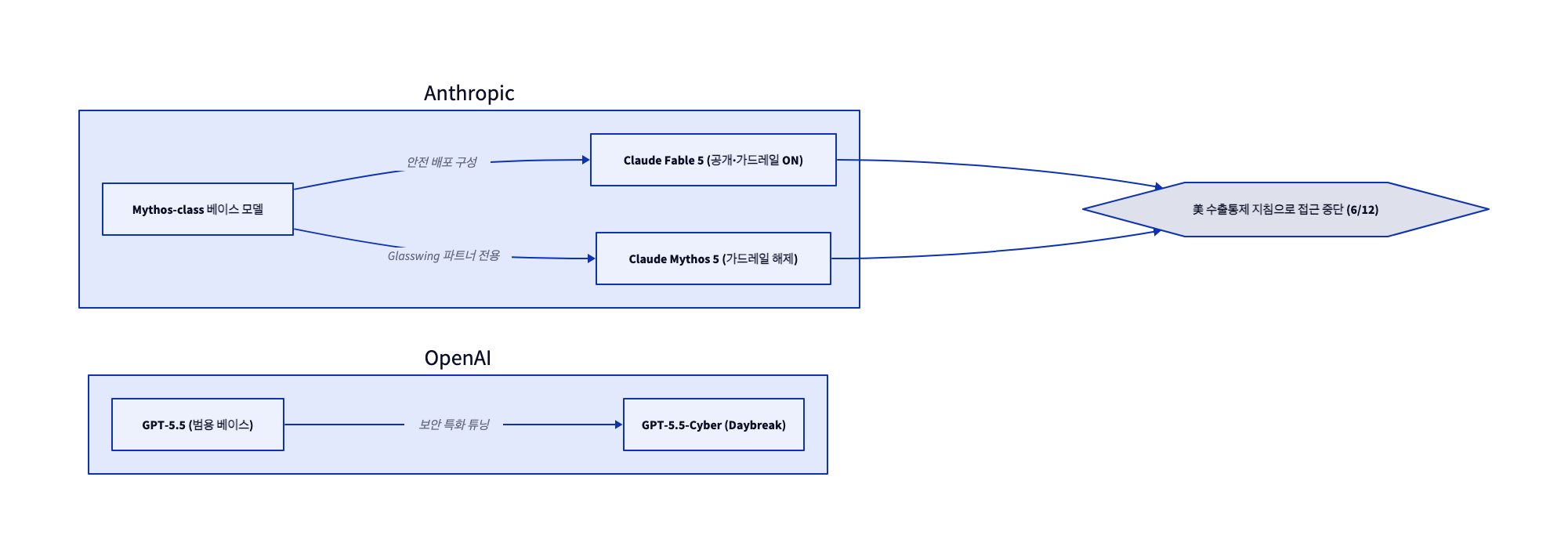
🔗 다이어그램 요약: Anthropic은 하나의 Mythos-class 베이스에서 공개·가드레일 모델 Fable 5와 가드레일 해제 모델 Mythos 5를 갈라 냈고, OpenAI는 범용 GPT-5.5를 보안 특화로 튜닝해 GPT-5.5-Cyber를 만들었다. Fable 5와 Mythos 5는 6월 12일 미국 수출통제 지침으로 접근이 중단됐다.
🟢 OpenAI — Daybreak와 GPT-5.5-Cyber
Daybreak는 소프트웨어 취약점을 대규모로 식별·검증·패치하는 방어자(Defender) 중심 보안 플랫폼이다. 2026년 6월 22일 OpenAI는 이 플랫폼을 확장하며 GPT-5.5-Cyber 정식(full) 버전을 공개했다.
함께 발표된 것이 주요 오픈소스의 결함을 대규모로 고치는 ‘Patch the Planet’ 이니셔티브, Codex Security 플러그인 업데이트, 그리고 Cisco·CrowdStrike·Palo Alto Networks·IBM 등 24곳 이상이 참여하는 Cyber Partner Program이다.
▶ 접근 정책: 일반 공개가 아니다. 신원이 검증된 ‘신뢰할 수 있는 방어자(verified trusted defenders)’에게만 제한 제공된다. 국가 단위로는 호주·캐나다·프랑스·독일·일본·한국, 그리고 ENISA 등 EU 기관이 ‘Trusted Access for Cyber’ 파트너로 확인됐다.
🟢 Anthropic — Project Glasswing과 Fable 5 / Mythos 5
Project Glasswing은 세계 핵심 소프트웨어를 방어하기 위한 Anthropic 주도 연합이다. 2026년 4월경 약 50개 초기 파트너가 ‘Mythos Preview’에 접근해 고위험·치명 등급 결함 1만 건 이상을 찾아냈고, 이후 15개국 이상 약 150개 기관으로 확대됐다.
Fable 5와 Mythos 5는 같은 베이스의 두 배포 구성이다. Fable 5는 일반 공개 모델로 사이버·생물학 같은 고위험 쿼리에 강력한 가드레일을 적용해 민감 질의를 자동으로 Claude Opus 4.8로 우회한다. Mythos 5는 가드레일을 해제한 버전으로 Glasswing 검증 파트너에게만 제공되며, Anthropic은 이를 “세계 어떤 모델보다 강력한 사이버 보안 능력”으로 소개했다.
벤치마크 성능 — CyberGym에서 누가 앞서나
비교의 핵심은 CyberGym이다. UC Berkeley가 188개 프로젝트의 실제 취약점 1,507건으로 구축한 벤치마크로, AI 에이전트가 통제된 환경에서 알려진 취약점을 재현·검증하는 능력을 측정한다. 단순히 코드를 읽는 수준을 넘어, 결함을 실제로 트리거하고 그것이 진짜 취약점임을 확인하는 데까지 가야 점수를 받는다.
아래는 발표 기준 세 벤치마크의 수치다.
| 모델 | CyberGym | ExploitGym | SEC-bench Pro |
|---|---|---|---|
| GPT-5.5-Cyber | 85.6% | 39.5% | 69.8% |
| GPT-5.5 (범용 베이스) | 81.8% | 25.95% | 63.1% |
| Anthropic Mythos 5 | 83.8% | — | — |
| Claude Opus 4 | 73.1% | — | — |
헤드라인 지표인 CyberGym만 막대로 보면 격차의 크기가 더 또렷하다.
여기서 한 가지 짚어둘 점이 있다. GPT-5.5-Cyber를 Mythos·Fable에 ‘버금가는’ 수준으로 보는 시각이 흔하지만, 적어도 CyberGym 단일 지표에서는 결이 다르다. OpenAI는 자사 모델이 Mythos 5를 1.8%p 앞선다(85.6% vs 83.8%)고 명시적으로 주장했다. ‘따라잡았다’가 아니라 ‘근소하게 추월했다’는 것이 OpenAI의 마케팅 프레임이다.
🧠 이 우위는 신중히 읽어야 한다.
① 모든 수치가 OpenAI 측 발표 기준이며 독립 재현 검증은 아직 공개되지 않았다.
② ExploitGym·SEC-bench Pro에 대한 Mythos 5 점수는 공표되지 않아 세 벤치마크 전반의 우열은 단정할 수 없다.
③ 비교 대상이 비대칭이다. 사이버 특화 모델 GPT-5.5-Cyber의 진짜 카운터파트는 공개 모델 Fable 5가 아니라 가드레일 해제 모델 Mythos 5다. Fable 5는 애초에 민감 사이버 쿼리를 Opus 4.8로 우회시키므로 같은 선상의 비교 대상이 아니다.
초기 보도와 후속 보도가 엇갈렸던 지점
발표 직후 보도와 이후 정리된 보도 사이에서 세 가지가 엇갈렸다. 견해가 갈렸던 지점을 1차 자료로 확정한다.
🟡 출시일 불일치 — 한쪽은 “2026-06-09 출시”, 다른 쪽은 “4월 및 6월”이라 했다. 실은 둘 다 부분적으로 맞다. Project Glasswing과 Mythos Preview는 4월에 시작됐고, 정식 Fable 5·Mythos 5 모델 출시는 6월 9일이다. ‘4월’은 이니셔티브·프리뷰, ‘6월 9일’은 모델 정식 출시를 가리킨 것으로, 두 사건을 구분하면 모순이 풀린다.
🟡 Mythos 5 점수 ‘비공개’ vs ‘83.8%’ — 한쪽은 Mythos 5 점수를 비공개라 했으나, OpenAI가 자사 발표에서 비교군으로 83.8%를 직접 제시했다. 따라서 ‘비공개’는 부정확하고, 83.8%가 확정 수치다.
🔴 ‘접근 중단’이 실제인가 — 사실이다. 2026년 6월 12일, Anthropic은 미국 정부의 수출통제 지침에 따라 Fable 5·Mythos 5에 대한 전 고객 접근을 중단했다.
접근 중단 사태 — 수출통제가 부른 오프라인
정부 지침의 핵심은 외국 국적자 전원(미국 내외 불문, 외국인 직원 포함)의 접근 차단이었다. 정부가 문제 삼은 것은 Fable 5의 가드레일을 우회(jailbreak)하는 방법이 발견됐다는 점이다. 취약점 탐지 같은 사이버 작업 제한을 무력화할 수 있는 경로가 생겼다는 것이다.
Anthropic은 “수억 명에게 배포된 상용 모델을 좁은 우회 가능성 하나로 회수하라는 기준을 업계 전반에 적용하면 모든 프런티어 모델 출시가 사실상 중단될 것”이라며 반발했고, “오해라 보며 가능한 한 빨리 접근을 복구하겠다”고 밝혔다. 6월 22일 기준 두 모델은 여전히 오프라인 상태다. 같은 시기 Five Eyes(미·영·캐·호·뉴 정보동맹)는 “AI 기반 공격이 수개월 내 현실화될 수 있다”고 경고했다.
4월 프리뷰부터 6월 접근 중단, 그리고 OpenAI의 정식판 공개까지의 흐름은 다음과 같다.
Preview 시작
정식 출시
접근 중단
정식판·Patch the Planet
각 모델의 강점과 도입 시 고려사항
세 모델의 강점은 다음과 같이 압축된다.
GPT-5.5-Cyber — 취약점 식별 → 검증 → 패치 코드 자동 생성에 이르는 엔드투엔드 교정(remediation) 파이프라인, 그리고 레드팀·익스플로잇 개발 등 공격자 관점을 방어에 접목하는 능력. CyberGym·ExploitGym·SEC-bench Pro 세 벤치마크에서 수치상 우위를 주장한다.
Mythos 5 — Glasswing 연합을 통한 국가·핵심 인프라 단위의 선제적 취약점 발굴. 50개 파트너가 결함 1만 건 이상을 실제로 찾아낸 운영 실적이 강점이다.
Fable 5 — 사이버 특화 모델이 아니라 강력한 가드레일을 갖춘 범용 에이전트 코딩·추론 모델. 민감 영역은 Opus 4.8로 우회한다.
💼 실무적 시사점
첫째, 최고 벤치마크 ≠ 사용 가능. Anthropic 사례가 보여주듯 SOTA 모델이라도 규제·안보 리스크로 하루아침에 차단될 수 있다. 이제는 공급 연속성(continuity of access)이 성능만큼 중요한 도입 기준이 됐다.
둘째, 벤치마크 수치는 전부 벤더 자체 발표이고 독립 재현이 아직 공개되지 않았다. 1.8%p 같은 근소한 격차를 의사결정의 결정타로 삼기엔 이르다.
셋째, 휴먼 인 더 루프는 여전히 전제다. AI가 생성한 패치·진단을 인간 검증 없이 시스템에 직결하는 것은 고위험이며, 최종 배포 권한을 사람이 통제하는 체계가 갖춰져야 한다.
참고 자료
▶ OpenAI — Daybreak: Securing the World
▶ Anthropic — Project Glasswing
▶ Anthropic — Claude Fable 5 · Mythos 5 발표
▶ Anthropic — Fable·Mythos 접근 중단 성명
▶ 그 외 보도: CNBC, TechCrunch, SiliconANGLE, Axios, Fortune
※ 본문의 벤치마크 수치·일정·접근 정책은 2026년 6월 기준 각 사 공식 발표와 보도를 정리한 것으로, 독립 재현 검증을 거치지 않은 벤더 자체 수치를 포함합니다. 정책·접근 가능 여부는 이후 변경될 수 있습니다.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-23