중국 5대 AI 모델 한눈에 비교 — 가격·로컬 구동·벤치마크
중국을 대표하는 5개 모델 — Qwen(알리바바)·DeepSeek·MiniMax·Kimi(문샷)·Mino — 의 API 가격, 로컬 PC 구동에 필요한 하드웨어, 그리고 발표된 벤치마크 성능을 Claude·OpenAI 모델과 한자리에 모았습니다. 가격은 서구 모델의 1/15~1/100 수준으로 확인되지만, 일부 벤치마크 점수와 버전명은 믿을 만한 출처가 부족했습니다. 그래서 이 글은 확인된 사실과 아직 미검증인 정보를 분명히 나눠서 정리합니다. 그래야 실제 도입 판단에 더 정직한 재료가 되기 때문입니다.
중국 AI는 어떻게 굴러가나 — ‘식스 타이거즈’와 투트랙 전략
중국 AI 산업은 ‘식스 타이거즈(Six Tigers)’로 불리는 신흥 기업군(딥시크·문샷·미니맥스 등)과 알리바바·바이트댄스·샤오미 같은 빅테크가 함께 끌고 갑니다. 이들이 공통으로 쓰는 무기가 바로 투트랙(Open & Proprietary) 전략입니다. 한쪽에선 최고 성능 모델을 클라우드 API 종량제로만 팔아 수익을 내고, 다른 한쪽에선 중소형 모델의 가중치를 무료로 풀어 전 세계 개발자를 자기 생태계로 끌어들입니다.
🔒 폐쇄형 플래그십 — 최고 성능 모델은 클라우드 API로만 과금 제공 (예: Qwen-Max 계열).
🔓 오픈 웨이트 — 중소형 모델을 무료 배포해 글로벌 개발자 생태계 장악 (예: Qwen 7B~72B, DeepSeek 오픈 가중치, 샤오미 MiMo).
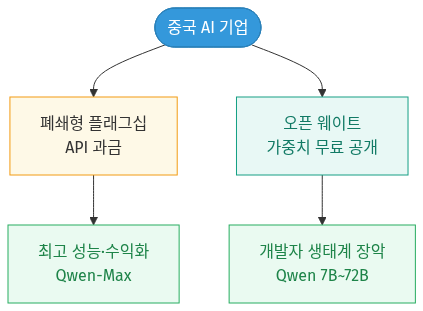
🔗 다이어그램 요약: 중국 AI 기업은 한 갈래로는 최고 성능 모델을 유료 API로 팔아 돈을 벌고(폐쇄형), 다른 갈래로는 중소형 모델 가중치를 무료로 풀어 개발자 생태계를 장악합니다(오픈 웨이트).
먼저 알아 둘 세 가지 — MoE·양자화·통합 메모리
가격표와 하드웨어 표를 제대로 읽으려면 용어 셋이 필요합니다. 어렵지 않습니다.
MoE(전문가 혼합) — 전체 파라미터 중 일부 ‘전문가’만 추론에 동원하는 구조입니다. DeepSeek V3는 총 671B이지만 실제 추론 때 켜지는 건 약 37B뿐입니다. 함정은, 추론 비용은 싸지지만 가중치 전체를 메모리에 올려야 해서 로컬 구동에 필요한 메모리는 전혀 줄지 않는다는 점입니다.
양자화 — 가중치 정밀도를 낮춰(FP16→4-bit) 메모리를 아끼는 기법입니다. 개인이 모델을 돌릴 때 사실상 표준은 4-bit(Q4_K_M)입니다.
통합 메모리 — 애플 실리콘(Mac)은 CPU와 GPU가 메모리를 함께 쓰기 때문에, 별도 그래픽 메모리(VRAM) 없이도 시스템 메모리만으로 큰 언어 모델을 돌릴 수 있습니다.
‘Mino’는 누구인가 — 아직 정체가 갈린다
사용자가 지정한 5개 중 ‘Mino’의 정체는 자료마다 다르게 가리킵니다. 한쪽 자료에서는 커뮤니티에서 샤오미 MiMo와 면벽지능 MiniCPM을 섞어 부른다고 보고, 다른 자료에서는 샤오미가 ‘Human × Car × Home’ 생태계용으로 만든 MiMo(Mi + Model)로 못 박아 제시합니다.
🧠 이 글에서는 더 많은 자료가 가리키는 샤오미 MiMo를 ‘Mino’로 보되, 면벽지능 MiniCPM일 가능성도 완전히 배제하지는 않습니다. 즉, 추가 확인이 필요한 영역입니다.
1M 토큰당 가격 — 중국 모델이 압도적으로 싸다
가격은 공식 개발자 플랫폼에서 출처가 확인된 항목 위주로 정리했습니다(2026년 6월 기준, 1M 토큰당 USD). 다만 모델 세대명(버전)에서 자료 간 충돌이 있어 그대로 병기합니다.
| 모델 (제공사) | Input | Output | 비고 |
|---|---|---|---|
| Qwen-Turbo | ~$0.05 | ~$0.20 | 무료 티어 2026-04-15 종료 |
| Qwen-Plus | ~$0.40 | ~$1.20 | Bailian |
| Qwen3.7-Max | ~$1.25 | ~$3.75 | 자료에 따라 Output을 $7.50까지 보기도 |
| DeepSeek V3.2 | $0.14 | $0.28 | 캐시 적중 시 Input $0.014 (90%↓) |
| MiniMax-M2.5 | $0.15 | $1.20 | MiniMax Open Platform |
| MiniMax-M2.7 | $0.30 | $1.20 | MiniMax Open Platform |
| Kimi K2.5 | ~$0.60 | ~$3.00 | Moonshot |
| Kimi K2.6 / K2.7 Code | ~$0.95 | ~$4.00 | 캐시 읽기 시 Input ~$0.15–0.19 |
대조군으로 서구 프론티어 모델을 같은 단위로 두면 격차가 한눈에 들어옵니다.
| 모델 (제공사) | Input | Output |
|---|---|---|
| Claude 3.5 Sonnet | $3.00 | $15.00 |
| Claude Opus 4.8 | $5.00 | $25.00 |
| GPT-5.5 (OpenAI) | $5.00 | $30.00 |
출력 가격(1M 토큰당)을 막대로 그리면 중국 모델이 거의 보이지 않을 만큼 짧습니다. DeepSeek의 출력 $0.28은 GPT-5.5($30)의 약 1/100, Claude Opus 4.8($25)의 1/89 수준입니다.
🟡 가격에서 짚어 둘 충돌
• DeepSeek 버전명: 한 자료는 V3.2 단일 통합 모델을 공식 가격($0.14/$0.28)으로 제시했지만, 다른 자료는 V4-Pro($0.435/$0.87)·V4-Flash($0.14/$0.28)로 나눠 제시했습니다. ‘V4’ 라인업은 1차 출처가 확인되지 않아 실존 여부가 미검증입니다. 확인된 공식 가격은 V3.2 기준입니다.
• Kimi 출력 가격: 자료에 따라 ~$3.00(K2.5 세대)과 ~$4.00(K2.7 Code 세대)으로 모델 세대가 다릅니다.
• MiniMax: 세대명이 자료마다 어긋납니다(abab/M → M3 → M2.5/M2.7). 가장 최근·출처가 명시된 M2.x 기준을 우선했습니다.
로컬 PC로 돌릴 수 있나 — 파라미터별 하드웨어
모든 수치는 4-bit 양자화를 기준으로 합니다. 보안 때문에 사내에 직접 모델을 올리려는 곳이 늘면서 가장 많이 묻는 부분이기도 합니다.
Qwen 오픈 웨이트 — 가장 신뢰도 높은 구간
| 파라미터 | 적재 크기(4-bit) | 권장 NVIDIA | 권장 Mac |
|---|---|---|---|
| 7B~9B | ~6–8 GB | 8GB+ (RTX 3060/4060) | 16 GB |
| 14B | ~10–12 GB | 16GB+ VRAM | 16–24 GB |
| 32B~35B | ~20–22 GB | 24GB (RTX 3090/4090) | 32–48 GB |
| 72B | ~40–45 GB | 멀티 GPU (24GB ×2) | 64 GB+ |
DeepSeek V3 (671B MoE) — ‘소형 착시’에 주의
| 정밀도 | 요구 메모리 |
|---|---|
| FP16/BF16 | ~1.3–1.4 TB |
| FP8 | ~685 GB |
| 4-bit (AWQ/GGUF) | ~350–400 GB |
🔴 여기서 가장 큰 오해가 나옵니다. 어떤 자료의 표는 ‘DeepSeek V3’를 ’70B 이상’ 칸에 묶어 마치 128GB Mac으로도 구동 가능한 것처럼 적었습니다. 하지만 V3는 671B MoE라 4-bit로 깎아도 최소 350~400GB가 필요해, 128GB Mac의 한계를 한참 넘어섭니다. 활성 파라미터(~37B)만 보고 ‘소형’으로 착각하면 안 됩니다. 이 체급은 단일 워크스테이션이나 Mac으로는 사실상 로컬 구동이 불가능하고, 멀티 GPU 엔터프라이즈 서버가 필수입니다.
Mino(샤오미 MiMo) — 버전 수치는 미검증
아래는 한 자료 기준이며, 버전명과 파라미터 수치 모두 1차 출처가 부족해 미검증입니다.
• MiMo-7B(밀집) — ~8–12 GB VRAM. RTX 3060/4060급 단일 GPU로 구동 가능.
• MiMo-V2-Flash(총 309B / 활성 15B) — Q4 최소 ~32GB부터 FP8 ~160GB. 컨슈머 환경은 24GB ×2 듀얼 + 무거운 양자화 필수.
• MiMo-V2.5-Pro(총 1T+ / 활성 42B) — FP8 ~370GB+. H100/B200급 클러스터 필요.
벤치마크 점수, 왜 그대로 믿으면 안 되나
이 부분이 가장 신뢰도가 낮습니다. 두 자료가 서로 다른 벤치마크 체계와 서로 다른 비교군을 써서, 단일 대차대조표 자체가 성립하지 않습니다. 그래서 합치지 않고 그대로 나눠 보여드립니다.
구세대 지표 (MMLU·HumanEval·GSM8K, 2024 비교군)
| 모델 | MMLU | HumanEval | GSM8K |
|---|---|---|---|
| Claude 3.5 Sonnet | 88.7% | 92.0% | 96.4% |
| GPT-4o | 88.7% | 90.2% | 95.6% |
| DeepSeek V3 | 88.5% | 89.0% | 98.2% |
| Qwen-Max | 88.0% | 88.5% | 98.0% |
| Kimi K2.6 | ~86% | ~85% | ~96% |
| MiniMax | ~85% | ~83% | ~95% |
| Mino/MiMo | ~82% | ~80% | ~92% |
신세대 지표 (LiveCodeBench·GPQA Diamond·MMLU-Pro, 2026 비교군)
| 모델 | LiveCodeBench | GPQA Diamond | MMLU-Pro |
|---|---|---|---|
| Qwen 3.7 Max | 91.6% | 92.4% | 89.6% |
| DeepSeek V4 Pro | 93.5% | 90.1% | 87.5% |
| MiniMax M3 | High | ~93.0% | N/A |
| Kimi K2.7-Code | 82.05% | High | N/A |
| Claude Fable 5 | SWE 리드 | 94.1% | N/A |
| GPT-5.5 | N/A | 94.0% | N/A |
🔴 벤치마크를 읽을 때 반드시 인지할 세 가지
1. 시점 불일치 — 구세대 표는 가격은 ‘2026년’이라면서 비교군은 2024년 모델(Claude 3.5 Sonnet·GPT-4o)을 썼습니다. 2026년 프론티어(Claude Opus 4.x/Fable 5, GPT-5 계열)와 견줘야 의미가 있습니다.
2. 잣대 단절 — MMLU·HumanEval·GSM8K는 상위 모델이 90%+로 이미 포화돼 변별력을 잃었고, 업계는 SWE-bench Verified·LiveCodeBench 같은 에이전틱 벤치마크로 옮겨갔습니다. 두 표는 자(尺)가 달라 한 줄로 합칠 수 없습니다.
3. 출처 부재 — 양 표의 점수 다수와 DeepSeek V4·Qwen 3.6/3.7·Kimi K2.6·MiMo V2.5 같은 버전명이 검증 가능한 1차 출처 없이 제시됐습니다. 참고용 정황 수치로만 다루고, 도입 전 자체 벤치마크가 반드시 선행돼야 합니다.
왜 이렇게 싸고, 또 비슷해졌나
① 성능의 상향 평준화. 중국 기업들은 MoE 아키텍처에 대규모 자본을 쏟고 글로벌 오픈소스 성과를 빠르게 흡수했습니다. 그 결과 이미 포화된 전통 벤치마크에서는 서구 최상위와의 격차가 거의 사라졌습니다 — 단, ‘포화된 지표 기준’이라는 단서가 붙습니다. 에이전틱·실무 코딩(SWE-bench)에서의 진짜 격차는 위 자료만으로 단정할 수 없습니다.
② 초저가의 구조적 배경. 성능이 엇비슷해지자 가격이 유일한 차별점이 됐고, 생태계 록인을 노린 의도적 출혈 경쟁이 벌어집니다. 앞서 본 대로 DeepSeek의 출력 $0.28은 GPT-5.5의 약 1/100, Claude Opus 4.8의 1/89 수준입니다.
③ 캐싱의 보편화. 2026년 모델들의 공통 특징입니다. DeepSeek은 캐시 적중 시 입력을 90% 할인하고, Kimi도 캐시 읽기를 별도 저가로 책정합니다. 반복 프롬프트가 많은 프로덕션에서는 표기가보다 실효 단가가 더 내려갑니다.
시장에 미치는 영향 — 가격 인하·온프레미스·라우팅
• 가격 하방 압력 — 중국 모델이 ‘GPT-4o급 성능을 1/15~1/100 가격’으로 내놓으면서, 글로벌 API 단가 전반에 지속적인 인하 압력이 작용합니다.
• 로컬·온프레미스 확산 — 데이터 유출을 꺼리는 기업·규제기관은 Qwen 7B~32B나 MiMo-7B를 RTX 3090/4090급 또는 32~48GB Mac에 직접 올리는 사례가 늘고 있습니다. 반면 DeepSeek V3급 671B MoE는 진입장벽(350GB+)이 너무 높아 사실상 클라우드 전용입니다.
• 용도별 라우팅 표준화 — 단순 요약·번역은 초저가 중국/로컬 모델로, 복합 추론·고난도 코딩은 Claude·GPT 상위 모델로 분기하는 하이브리드 전략이 업계 표준으로 자리 잡고 있습니다.
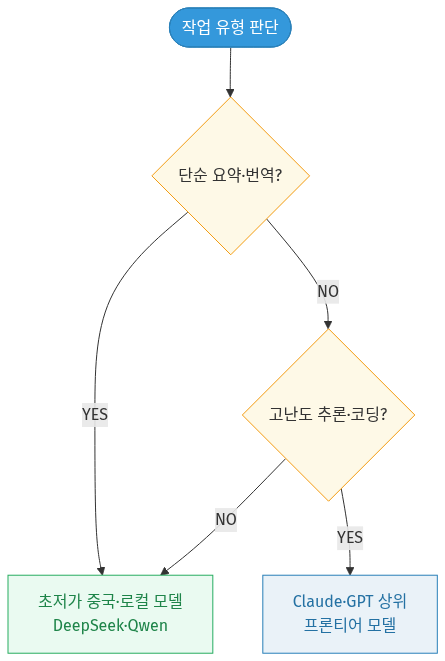
🔁 다이어그램 요약: 작업이 단순 요약·번역이면 초저가 중국·로컬 모델로 보내고, 고난도 추론·코딩이면 Claude·GPT 상위 모델로 라우팅합니다. 어느 쪽도 아닌 일반 작업은 저가 모델로 처리해 비용을 아낍니다.
어떤 모델을 골라야 하나 — 용도별 결론
🟢 API 비용 절감이 최우선이라면 — DeepSeek V3.2($0.14/$0.28)가 검증된 최저가 구간입니다. 초장문 문맥은 Kimi, 엔터테인먼트·캐릭터 B2C는 MiniMax-M2.x가 강점입니다.
💼 보안 때문에 온프레미스가 필요하다면 — Qwen 7B~32B 또는 MiMo-7B를 24GB VRAM GPU 또는 32~48GB Mac에 올리는 것이 가장 현실적이고 경제적입니다.
🔴 거대 MoE의 로컬 구동은 비현실적 — DeepSeek V3급은 멀티 H100 서버 없이는 불가능합니다. 처음부터 클라우드 전용으로 설계하세요.
🧠 권고: 실제 도입 전, 자사 핵심 업무(코딩·한국어 추론 등)에 맞춘 자체 블라인드 벤치마크가 필수입니다. 공개 점수는 마케팅·데이터 오염 가능성이 있고, 한국어 뉘앙스나 복합 추론에서는 여전히 Claude·GPT 계열이 미세 우위를 보이는 경우가 보고됩니다.
정직하게 남겨 두는 한계
이 정리에서 확실한 것과 불확실한 것을 다시 한 번 구분합니다. 가격과 Qwen 로컬 사양은 공식 플랫폼 출처가 확인됩니다. 반면 벤치마크 점수와 일부 버전명(DeepSeek V4, Qwen 3.6/3.7, MiMo V2.5 등)은 1차 출처가 불충분하므로 성능 수치는 정황 참고용으로만 활용해야 합니다. 비교표 역시 세대 불일치(2024 vs 2026 비교군, 포화 지표 vs 에이전틱 지표) 탓에 완전한 1:1 대조가 되지 않으며, ‘Mino’의 정체(샤오미 MiMo vs 면벽지능 MiniCPM)도 아직 미확정입니다.
⚠️ 본 자료의 가격·하드웨어·벤치마크 수치는 공개된 시점(2026년 6월) 기준이며, 일부 항목은 1차 출처가 확인되지 않은 정황 정보입니다. 모델 가격과 라인업은 수시로 바뀌므로, 실제 도입·구매 결정 전 각 공식 플랫폼의 최신 고지와 자체 검증을 반드시 거치시기 바랍니다.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-15