ARM CPU의 MMU 완전 정복 — 페이지 테이블은 누가, 언제, 어떻게 다루나
가상 주소 변환 · pagetable.S · TLB · Buddy Allocator — 펌웨어와 OS 커널의 역할 분담
ARM Cortex-A55 같은 ARMv8-A 계열 프로세서를 다루다 보면 반드시 마주치는 부품이 바로 MMU(Memory Management Unit, 메모리 관리 장치)입니다. CPU가 쓰는 주소를 실제 RAM 주소로 바꿔 주고, 메모리를 보호하고, 특정 영역의 캐시 정책까지 결정하는 시스템의 두뇌죠. 이 글에서는 MMU가 정확히 무슨 일을 하는지, 그 핵심인 페이지 테이블(Page Table)을 누가·언제·어디서 관리하는지, 그리고 “메모리에서 테이블을 읽는다”는 구조적 약점에도 왜 시스템이 느려지지 않는지를 하드웨어와 소프트웨어의 역할 분담 관점에서 차근차근 풀어보겠습니다.
🧠 MMU란 무엇인가 — 가상 주소를 물리 주소로 바꾸는 통역사
MMU는 CPU 코어와 물리 메모리(RAM) 사이에 자리 잡고, CPU가 사용하는 가상 주소(Virtual Address)를 실제 RAM의 물리 주소(Physical Address)로 변환해 주는 하드웨어 블록입니다. 비유하자면, 프로그램은 “내 집 주소”라는 깔끔하게 정리된 가상의 번지를 쓰고, MMU는 그 번지를 실제 도시 어딘가의 진짜 위치로 바꿔주는 통역사인 셈입니다.

🔗 다이어그램 요약: CPU가 보낸 가상 주소는 MMU를 거쳐 물리 메모리로 변환된다 — 변환표가 MMU 안 TLB 캐시에 없을 때만(TLB Miss) 메모리의 페이지 테이블을 직접 뒤지는 우회로(Table Walk)를 탄다.
MMU의 세 가지 임무
① 주소 변환 — 물리 메모리의 제약을 감추고, 각 프로세스에게 마치 독차지한 듯한 연속적이고 거대한 가상 주소 공간을 제공합니다.
② 메모리 보호 — 프로세스끼리 서로의 영역을 침범하지 못하게 격리하고, 사용자(User) 권한과 커널(Kernel) 권한 영역을 분리합니다.
③ 메모리 속성 제어 — 특정 주소 대역이 캐시 가능한 일반 메모리인지, 디바이스 I/O 영역인지, Secure 영역인지를 정의합니다. pagetable.S에서 보던 “Secure/Non-secure, Shareable, Device” 표기가 바로 이 속성 제어입니다.
MMU를 움직이는 세 레지스터 (AArch64 기준)
소프트웨어는 메모리에 페이지 테이블을 만들어 두고, 그 시작 주소를 레지스터에 알려준 뒤, 변환 규칙과 속성을 정의하고, 마지막으로 MMU enable 비트를 켭니다. 그 순간부터 모든 메모리 접근이 MMU를 거칩니다.
| 레지스터 | 역할 |
|---|---|
| TTBR | Translation Table Base Register — 지금 쓰는 페이지 테이블이 메모리의 어디서 시작하는지(베이스 주소)를 담는다 |
| TCR | Translation Control Register — 페이지(Granule) 크기(예: 4KB) 등 변환 규칙을 설정한다 |
| MAIR | Memory Attribute Indirection Register — Device·Normal·Non-cacheable 등 메모리 속성을 정의하는 ‘팔레트’ 역할을 한다 |
⚙️ pagetable.S의 정체 — 부팅 초기의 정적 메모리 매핑
Cortex-A55 환경의 pagetable.S에서 특정 주소에 캐시 우회(Device)나 Secure 설정을 미리 넣어야 데이터가 캐시에 쌓이지 않고 곧바로 입출력되는 장면을 본 적이 있을 겁니다. 이것이 바로 부팅 초기 단계의 정적(static) 메모리 매핑입니다. 그리고 페이지 테이블의 관리 주체는 시간에 따라 명확히 바뀝니다.
1단계 — 부트로더 / 펌웨어 (정적 할당)
▶ 누가 — Trusted Firmware-A(TF-A), U-Boot 같은 저수준 펌웨어·부트로더 코드. pagetable.S는 보통 이 단계의 어셈블리 코드입니다.
▶ 언제 — 전원이 켜지고 Linux 같은 OS 커널로 진입하기 전, 하드웨어를 초기화하는 시점.
▶ 어디서 — 물리 메모리의 고정된 위치에 하드코딩된 페이지 테이블을 생성.
▶ 왜 — OS 구동 전에도 UART·GPIO 같은 하드웨어 레지스터와 통신하려면 MMU를 켜야 할 때가 있습니다. 이때 하드웨어 제어 레지스터 주소가 캐시에 저장되면 CPU가 실제 하드웨어의 상태 변화를 인지하지 못합니다.
💡 그래서 MAIR로 해당 대역을 Device-nGnRnE(캐시 안 됨, 재배치·병합 안 됨) 속성으로 지정해, 입출력이 즉각 반영되게 만듭니다. “캐시에 안 쌓이고 바로바로 출력되는” 그 동작이 정확히 이 메커니즘입니다. 반대로 Device 영역을 캐시 가능 속성으로 잘못 매핑하면, 값이 캐시에 갇혀 하드웨어로 바로 나가지 않는 골치 아픈 버그가 생깁니다.
2단계 — OS 커널 (동적 할당)
부팅이 끝나면 주도권은 Linux 커널의 메모리 관리 서브시스템(MM Subsystem)으로 넘어갑니다. 여기서 가장 중요한 사실 하나 — CPU 하드웨어 스스로는 어디가 빈 메모리인지 전혀 알지 못합니다. 빈 공간을 추적하는 것은 100% 소프트웨어의 일입니다.
▶ 빈 공간을 아는 방법 — 커널 내부의 Buddy Allocator 알고리즘이 전체 RAM을 4KB(또는 그 이상) 단위의 ‘페이지 프레임’으로 쪼갠 뒤, 사용 중인 곳과 비어 있는 곳을 거대한 장부(자료구조)에 기록·관리합니다.
▶ 업데이트 시점 — 사용자가 프로그램을 실행하거나 malloc()으로 메모리를 요청하면, Buddy Allocator가 남은 물리 번지를 찾아 해당 프로세스의 페이지 테이블 항목(PTE)에 물리 주소와 권한을 기록합니다.
관리 주체가 시간에 따라 바뀌는 흐름을 한눈에 보면 이렇습니다.
📌 핵심 정리 — 초기 틀은 펌웨어/부트로더가 만들지만, 그 이후의 수정·업데이트는 전적으로 OS 커널(소프트웨어)이 담당합니다. 즉 페이지 테이블을 “수정·업데이트하는 주체”는 부트 펌웨어 → OS 커널로 바뀝니다.
🧩 MMU가 메모리 ‘조각남’을 없애는 원리
단편화(Fragmentation)란 전체 빈 공간은 충분한데도 여기저기 �게 쪼개져 있어서 큰 덩어리를 할당하지 못하는 현상(외부 단편화)입니다. 옷장에 빈칸은 많은데 정작 큰 코트 하나 걸 연속된 공간이 없는 상황과 같죠. MMU 기반의 페이징(Paging)은 이 문제를 근본적으로 해소합니다.
▶ 원리 — 물리 메모리를 고정 크기(예: 4KB) 조각(Page Frame)으로 미리 잘라 둡니다. 프로세스는 예컨대 100MB의 연속된 가상 메모리를 요청합니다.
▶ 해결 — OS는 물리 메모리 여기저기 흩어진 불연속 4KB 덩어리들을 모아 페이지 테이블에 기록합니다. MMU는 프로세스가 연속된 가상 주소로 접근할 때 이를 흩어진 물리 주소로 즉시 매핑합니다.
▶ 결론 — 소프트웨어 눈에는 “완벽히 연속된 하나의 청크”로 보이지만, 하드웨어 단에서는 흩어진 공간을 알뜰히 조립해 쓰는 것이므로 물리 메모리의 외부 단편화가 발생하지 않습니다.
🚀 테이블을 메모리에 두는데 왜 안 느릴까 — TLB의 방어
MMU가 주소를 변환하려면 메모리에 있는 페이지 테이블을 읽어와야 합니다. 이 과정을 Translation Table Walk(TTW)라 부릅니다. 그런데 메모리 접근은 CPU 연산보다 훨씬 느려서(수백 사이클), 매 접근마다 테이블을 읽는다면 성능이 치명적으로 무너져야 정상입니다. 그럼에도 실제 성능 저하가 거의 없는 비결은 MMU 내부의 초고속 하드웨어 캐시 TLB(Translation Lookaside Buffer) 덕분입니다.
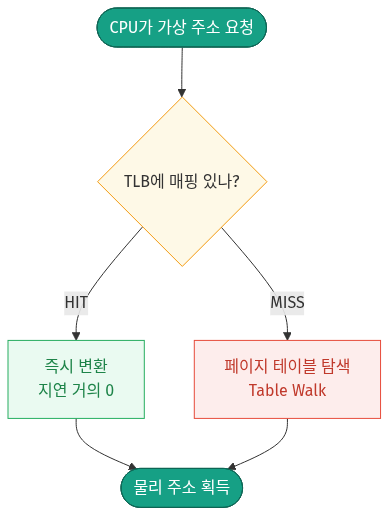
🔁 다이어그램 요약: 주소 변환은 TLB 적중 여부로 갈린다 — TLB에 매핑이 있으면(HIT) 즉시 변환되어 지연이 거의 0이고, 없을 때만(MISS) 느린 페이지 테이블 탐색(Table Walk)을 거친다.
① TLB의 역할 — 가장 최근에 변환한 (가상→물리) 매핑 쌍과 그 속성을 CPU 코어 내부의 초고속 SRAM에 저장합니다.
② 동작 순서 — CPU가 가상 주소를 요청하면, MMU는 메모리의 페이지 테이블로 가기 전에 먼저 TLB부터 조회합니다(TLB Hit 시 지연 거의 0).
③ Table Walk 발생 시점 — TLB에 정보가 없는 TLB Miss일 때만 메모리의 페이지 테이블을 뒤지는 TTW가 일어납니다.
④ 지역성의 법칙 — 프로그램은 한 번 접근한 메모리 근처를 다시 접근하는 경향(공간적 지역성)이 강해서, TLB Hit 비율이 통상 99% 이상으로 매우 높습니다.
실제 시스템에서의 TLB Hit 비율 (개념적 수치)
99%+ (지연 거의 0)
요컨대 “메모리에 테이블을 둔다”는 구조적 약점을 TLB라는 고속 하드웨어 캐시로 방어함으로써, 메모리 효율(파편화 방지)과 성능을 동시에 잡은 것입니다. 두 마리 토끼를 한 번에 잡는 영리한 설계죠.
✅ 정리 — 하드웨어와 소프트웨어의 명확한 역할 분담
① 역할 분담이 시간으로 나뉜다 — pagetable.S 같은 초기 코드는 시스템 구동과 필수 I/O 제어를 위한 ‘하드웨어적 기본 틀(속성·캐시 정책)’을 펌웨어/부트로더가 설계합니다. 이후의 동적 할당과 빈 메모리 추적은 온전히 OS 커널의 Buddy Allocator 몫입니다.
② 단편화 방지와 성능의 양립 — 외부 단편화를 막으려 페이징을 도입해 “테이블을 메모리에 두는” 약점을 감수했지만, 이를 TLB로 방어해 효율과 속도를 모두 챙겼습니다.
③ 펌웨어 엔지니어의 실무 시사점 — MAIR 레지스터와 초기 페이지 테이블 속성 관리가 캐시 꼬임이나 Data Abort를 막는 가장 중요한 요소입니다. Device 영역을 캐시 가능 속성으로 잘못 매핑하면 “캐시에 쌓여 바로 출력되지 않는” 버그가 생깁니다.
결론적으로 ARM Cortex-A 환경의 MMU는 단순 주소 변환기를 넘어, 시스템의 보안·캐시 일관성·입출력 정확성을 좌우하는 핵심 두뇌입니다. 하드웨어와 소프트웨어가 역할을 명확히 나눠, 한정된 메모리 자원을 안전하고·효율적이며·지연 없이 쓰도록 조율하는 시스템 아키텍처의 심장이라 할 수 있습니다.
📚 본 글은 ARM Architecture Reference Manual(ARMv8-A)과 Linux 커널 메모리 관리 문서의 일반적 동작 원리를 바탕으로 정리한 기술 해설입니다. 실제 SoC·부트로더 구현은 벤더와 보드 구성에 따라 세부가 다를 수 있으므로, 정밀한 설정은 해당 칩 레퍼런스 매뉴얼을 함께 확인하시길 권합니다.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-15