CPU 캐시는 어떻게 동작하는가 — 캐시 라인과 ARMv9 메모리 태깅
현대 프로세서 메모리 계층 · 64바이트 캐시 라인 · Set-Associative 매핑 · ARMv9 MTE까지 한 편으로 정리
프로세서의 실효 성능은 연산 코어의 클럭만으로 결정되지 않는다. 코어가 아무리 빨라도 데이터가 제때 공급되지 않으면 파이프라인은 멈춘다. 코어(3~5GHz)와 메인 메모리(DRAM, 접근 지연 수십 ns)의 속도 격차 — 흔히 메모리 벽(Memory Wall)이라 부르는 이 간극이 캐시(Cache)가 존재하는 근본 이유다. 이 글은 캐시 라인의 정의부터 하드웨어 구조, 매핑·운용 방식, 물리적 한계, 설계 원칙, 그리고 ARMv9의 메모리 태깅까지 차근차근 풀어낸다.
캐시는 왜 존재하는가 — 두 가지 지역성
캐시는 오랜 관찰에서 얻은 두 가지 경험적 원리 위에서 동작한다. 프로그램의 메모리 접근은 무작위가 아니라 일정한 쏠림이 있다는 사실이다.
캐시는 이 두 성질을 하드웨어로 적극 활용하는 장치다. 그리고 공간적 지역성을 활용하는 물리적 단위가 바로 캐시 라인이다.
캐시 라인 — 캐시 처리의 최소 단위
개념과 크기
캐시는 데이터를 1바이트나 1워드 단위로 관리하지 않는다. 캐시 라인(Cache Line, 또는 캐시 블록)이라 부르는 고정 크기 묶음으로 관리하며, 현대 x86·ARM 아키텍처에서 이 크기는 표준적으로 64바이트다. 인텔 최적화 매뉴얼과 헤네시·패터슨의 교과서 모두 64B 블록을 기준으로 분석한다.
“라인 단위 처리”의 의미와 동작
캐시를 “라인 단위로 처리한다”는 것은, CPU가 단 1바이트(char)만 요청해도 하드웨어는 그 바이트가 속한 64바이트 인접 영역을 통째로 가져온다는 뜻이다.
핵심 — fetch뿐 아니라 채움(fill), 축출(eviction), 일관성(coherence), 무효화(invalidation)까지 캐시의 모든 동작이 라인 단위로 일어난다. 이 라인 입도(granularity)는 뒤에서 다룰 거짓 공유(false sharing)의 원인이기도 하다.
하드웨어 구조와 효율성
캐시는 SRAM(Static RAM) 배열로 구현되며 크게 세 부분으로 구성된다.
CPU가 발생시킨 주소는 하드웨어에 의해 세 부분으로 쪼개져 해석된다 — Tag | Index | Offset. 아래 도식은 이 주소가 캐시 안에서 Hit/Miss로 판정되는 데이터 경로를 보여준다.
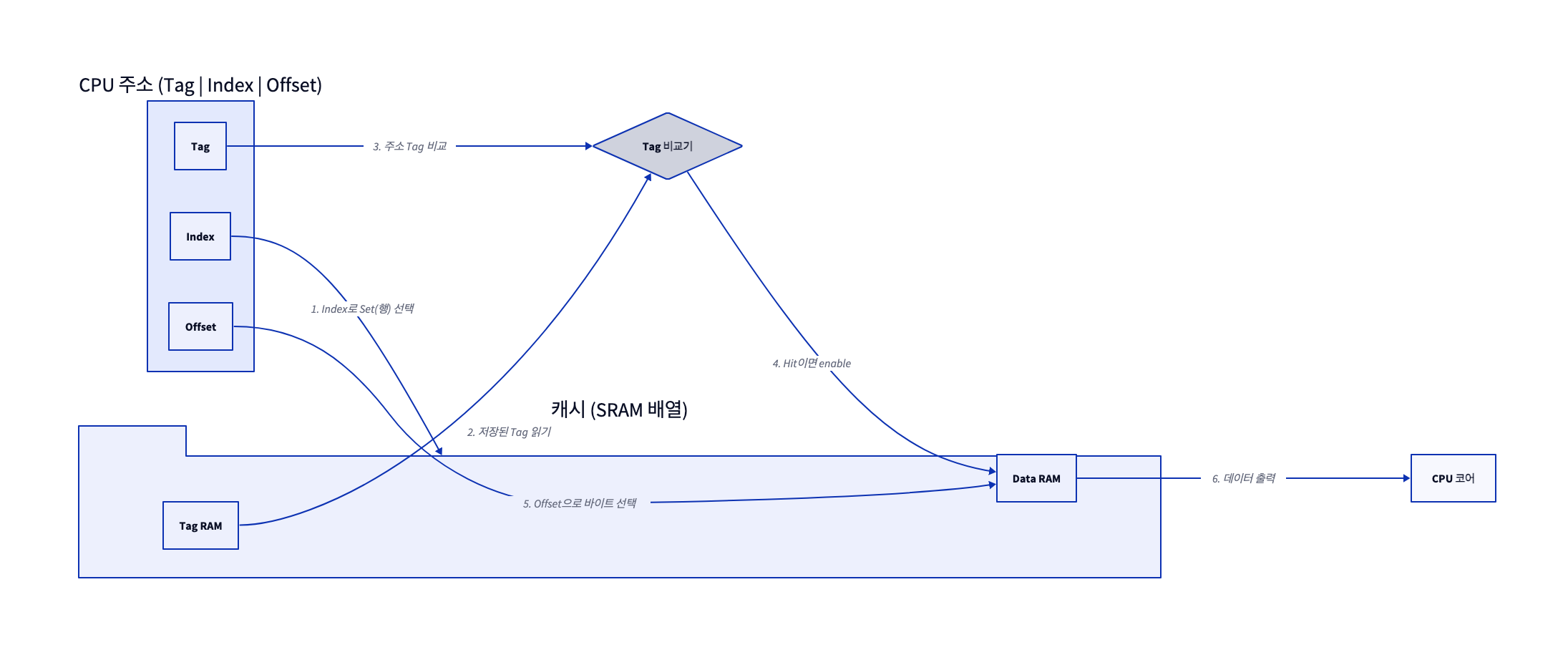
🔗 다이어그램 요약: CPU 주소는 Tag·Index·Offset 셋으로 쪼개진다. Index가 캐시의 Set(행)을 고르고, 그 자리에 저장된 Tag를 주소의 Tag와 비교기로 대조해 일치하면 Hit, 이어 Offset이 라인 안에서 정확한 바이트를 집어 코어로 내보낸다.
효율의 비밀은 병렬성과 무(無)소프트웨어 동작이다. Index 비트로 SRAM의 특정 행(Set)을 순식간에 활성화하고, 읽어낸 Tag를 주소의 Tag와 병렬 비교기(Comparator)로 단일 클럭에 대조한다. 운영체제나 소프트웨어 개입이 전혀 없는 100% 하드웨어 논리 회로이므로, L1 캐시 기준 4~5 클럭이라는 극단적으로 낮은 지연을 보장한다. 여기서 말하는 지연은 로드 명령이 실행된 시점부터 그 값에 의존하는 다음 명령이 데이터를 쓸 수 있게 되기까지의 사이클 수를 뜻한다.
캐시 크기 — 이점과 물리적 한계
캐시를 무한정 키우지 못하는 이유는 명확한 물리적 상충(Trade-off) 때문이다. 용량이 클수록 더 많은 데이터를 보관해 적중률(Hit Rate)이 오르고 메모리 병목이 완화된다. 그러나 그 대가가 만만치 않다.
이 한계의 해법이 계층적(Hierarchical) 설계다. 속도가 중요한 L1은 작고 매우 빠르게, 용량이 중요한 L3는 느리지만 크게 둔다. 코어에서 멀어질수록 느려지고 커지는 이 구조를 한눈에 보면 다음과 같다.

🔗 다이어그램 요약: 코어에서 멀어질수록 캐시는 느려지지만 커진다 — L1은 4~5 사이클로 가장 빠르고 작으며, L2·L3를 거쳐 DRAM은 400사이클 이상으로 가장 느리다. 이 계층화가 “크고 빠른 캐시는 불가능하다”는 물리 한계의 현실적 해답이다.
계층별 접근 지연을 표로 정리하면 상대 비용 구조가 분명해진다. 단, 아래 수치는 마이크로아키텍처(Skylake, Alder Lake 등)에 따라 편차가 있는 전형적인 값이다.
| 계층 | 대략적 접근 지연 | 상대 비용 |
|---|---|---|
| L1 | 4~5 cycle | 기준 (1×) |
| L2 | 12~14 cycle | 약 3× |
| L3 | 30~50+ cycle | 약 8~10× |
| DRAM | ~100ns / 400+ cycle | 약 80~100× |
데이터 저장·검색과 매핑
메인 메모리의 어느 블록을 캐시의 어느 자리에 둘지 정하는 규칙이 매핑(Mapping)이다. 주소의 Index가 “어느 Set로 갈지”를, Tag가 “그 자리의 데이터가 진짜 그 주소의 것인지”를 결정한다. 매핑 방식은 크게 세 가지로 나뉜다.
읽기 한 번이 어떻게 흘러가는지 전체 과정을 따라가 보자.
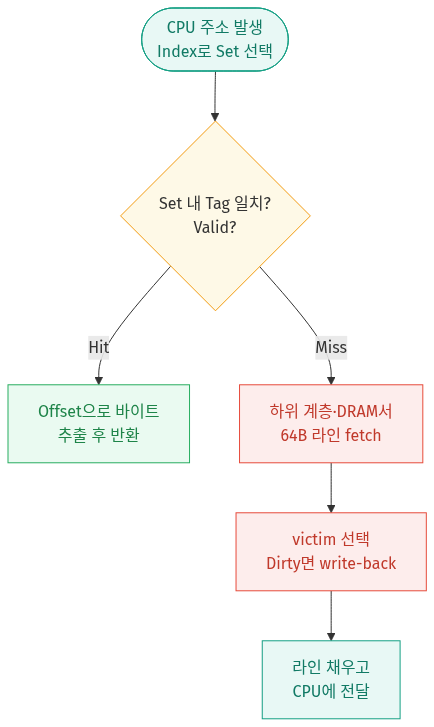
🔁 다이어그램 요약: 읽기 한 번은 Tag 일치 여부 하나로 갈린다 — 일치(Hit)면 Offset으로 바이트를 즉시 반환하고, 불일치(Miss)면 DRAM에서 64B 라인을 끌어와 victim을 교체(Dirty면 write-back 먼저)한 뒤 채워 CPU에 전달한다.
‘Tag’의 두 얼굴 — 식별용 캐시 태그와 ARMv9 메모리 태깅
“Tag”라는 용어는 캐시 맥락에서 서로 다른 두 가지를 가리킨다. 이 둘을 구분하는 것이 이 주제의 핵심이다. 하나는 데이터를 식별하는 전통적 캐시 태그이고, 다른 하나는 ARMv9에서 새로 도입된 보안용 메모리 태그다.
(a) 캐시 주소 태그 — 식별용 (전통적 Tag)
메인 메모리는 수십 GB인데 캐시는 수 MB에 불과하다. 따라서 캐시의 한 자리에는 여러 메모리 주소가 번갈아 매핑될 수밖에 없다. 지금 그 자리에 든 데이터가 정확히 어느 주소의 것인지 식별하려고 주소 상위 비트를 잘라 저장해 둔 것이 전통적 캐시 태그다. 이것이 Hit/Miss 판정의 근거다.
(b) ARMv9 메모리 태깅(MTE) — 보안용 (Allocation Tag)
ARMv9에서 “태그”가 보강된 것은 사실이며, 이는 Memory Tagging Extension(MTE)을 가리킨다. 다만 그 목적은 캐시 식별이 아니라 메모리 안전(Memory Safety)을 하드웨어로 강제하는 것으로, (a)와는 용도가 완전히 다르다. 즉 ARMv9의 태그 보강은 실재하는 기능이지만, 기존 식별용 캐시 태그가 확장된 것이 아니라 전혀 새로운 종류의 태그(보안용)가 캐시 인프라에 추가로 통합된 것이다.
정리하면, “ARMv9에서 태그가 보강된다”는 이해는 정확하다. 그것은 실재하는 MTE 기능이며, 다만 그 정체는 메모리 안전을 위한 4비트 할당 태그라는 점 — 그리고 Hit/Miss를 판정하는 식별용 캐시 태그와는 목적이 다른 별개 메커니즘이라는 점을 함께 알아 두면 된다.
캐시 시스템 설계의 필수 원칙
데이터 무결성과 성능을 동시에 지키려면 다음 네 가지를 반드시 보장해야 한다.
캐시의 이점과 타이밍 파형
캐시의 본질적 이점은 평균 메모리 접근 시간(AMAT)을 수십 ns에서 1ns 미만으로 단축한다는 점이다. AMAT은 대략 ‘Hit 시간 + Miss율 × Miss 패널티’로 표현되는데, 여기서 Miss 패널티가 워낙 커서 Miss율을 조금만 낮춰도 평균이 크게 좋아진다. Hit과 Miss의 지연 차이를 파형으로 보면 그 비대칭이 분명해진다.
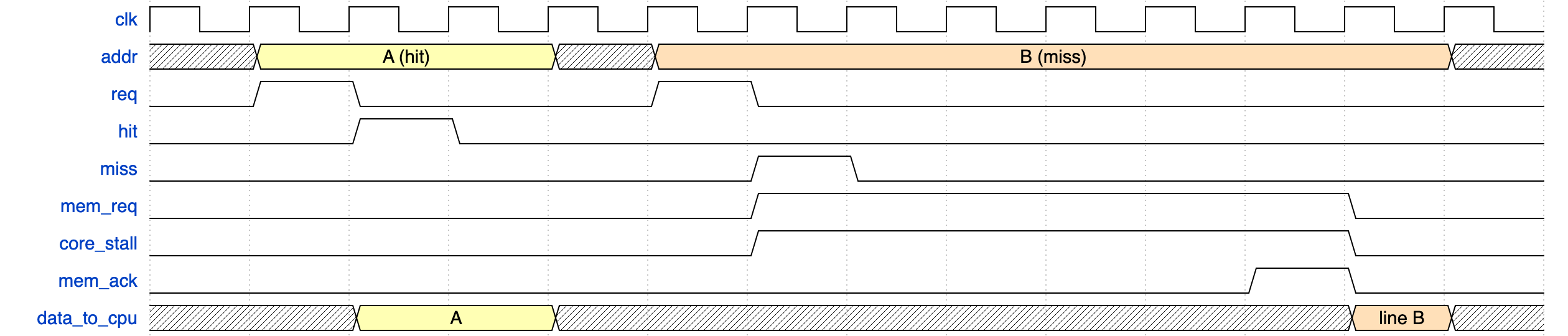
📊 파형 요약: Hit(주소 A)은 다음 클럭에 데이터가 바로 돌아오고 코어가 멈추지 않는다. Miss(주소 B)는 mem_req와 core_stall이 동시에 떠 수십 사이클 정지한 뒤 mem_ack가 와야 64B 라인이 채워져 데이터가 전달되고 stall이 풀린다.
① Cache Hit (주소 A) — req가 올라가고 다음 클럭에 hit이 확정된다(Tag 일치). data_to_cpu로 데이터 A가 곧바로 반환되며 core_stall은 전혀 발생하지 않는다. 코어는 멈추지 않고 파이프라인을 계속 진행한다(L1 기준 실제 약 4~5 사이클).
② Cache Miss (주소 B) — Tag 불일치로 miss가 뜨면 mem_req와 core_stall이 동시에 어서트된다. 코어는 메모리 응답을 기다리며 정지한다. mem_ack가 올 때까지 수십 사이클이 흐르고(DRAM ~100ns / 400+ cycle), 응답 후 64B 라인이 채워지며 데이터가 CPU로 전달되고 비로소 stall이 풀린다.
이 stall 시간의 막대한 비대칭을 막대로 그려 보면, 왜 적중률 한 끗이 그렇게 중요한지 한눈에 들어온다.
이 비대칭이, 적중률이 90%에서 95%로 단 5%만 올라도 시스템 성능이 극적으로 좋아지는 물리적 이유다. Miss 한 번의 비용이 Hit 수십~수백 번에 맞먹기 때문이다.
종합 시사점
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-27