🖥️ KVM과 QEMU, 가상 컴퓨터를 만드는 두 갈래의 기술
가상화 기술은 오늘날 클라우드와 데이터센터를 떠받치는 핵심 인프라다. 리눅스 진영의 표준으로 자리 잡은 KVM과 QEMU는 ‘하나의 물리 컴퓨터 위에 여러 대의 가상 컴퓨터를 띄운다’는 같은 목표를 전혀 다른 방식으로 풀어낸 두 기술이다. 흔히 한 묶음으로 불리지만 설계 사상과 중점 영역이 완전히 다르고, 현대 시스템은 이 둘을 결합해 쓴다. 컴퓨터 구조의 기초부터 실제 벤치마크 수치까지, 한 단계씩 짚어 본다.
🏗️ 출발점: 하이퍼바이저란 무엇인가
컴퓨터의 3계층과 OS의 ‘특권’
컴퓨터는 크게 세 층으로 나뉜다. 맨 아래에 물리적 하드웨어(CPU·메모리·디스크)가 있고, 그 위에 운영체제(OS)가 있으며, 가장 위에서 사용자의 애플리케이션(브라우저·게임)이 돈다. 현대 OS는 하드웨어를 독점 통제하는 ‘관리자’다. 여러 프로그램이 동시에 돌 때 누가 CPU를 얼마나 쓸지, 메모리 어느 영역을 쓸지를 OS가 특권 모드(privileged mode)에서 철저히 통제해 충돌을 막는다. CPU가 일반 사용자 코드와 OS 코드의 권한을 물리적으로 구분(흔히 ‘Ring 0~3’으로 표현)하기 때문에 가능한 통제다.
🍳 초심자를 위한 비유 — 식당 주방. 컴퓨터를 대형 주방이라 하면 화구가 CPU, 냉장고가 메모리, 창고가 디스크, 총괄 주방장이 OS다. 원칙적으로 한 주방엔 총괄 주방장이 한 명이어야 한다. 한식 주방장(Linux)과 양식 주방장(Windows)이 같은 화구를 서로 먼저 쓰겠다고 다투면 주방은 마비된다. 이것이 물리 컴퓨터 한 대에 OS 두 개를 그냥은 못 띄우는 근본 이유다.
하이퍼바이저의 역할
이 한계를 깨는 것이 하이퍼바이저(Hypervisor), 다른 말로 가상 머신 모니터(VMM)다. 하이퍼바이저는 주방장들 위에 선 ‘레스토랑 총괄 매니저’에 해당한다. 물리 주방을 유리벽으로 나누어 여러 개의 가상 머신(VM)을 만들고, 각 칸에 다른 주방장(Guest OS)을 배치한다. 각 게스트 OS는 자기가 하드웨어를 독점한다고 ‘착각’하지만, 실제로는 하이퍼바이저가 명령을 가로채 화구와 냉장고를 밀리초 단위로 쪼개 번갈아 배분한다.
✅ 왜 필요한가. 과거엔 거대한 서버 한 대에 OS 하나만 깔아 자원의 10~20%만 쓰는 낭비가 컸다. 하이퍼바이저로 유휴 자원을 여러 가상 컴퓨터에 나눠 주면 비용 절감과 자원 효율이 극대화된다. AWS·구글 클라우드 같은 인프라 서비스가 전부 이 기술 위에서 돌아간다.
⚙️ 핵심 차이: 가상화(KVM) vs 에뮬레이터(QEMU)
QEMU — 소프트웨어 중심 에뮬레이터
QEMU(Quick Emulator)는 순수한 소프트웨어 에뮬레이터다. 가상의 하드웨어 전체를 소프트웨어로 흉내 내며, 게스트가 내리는 명령어를 QEMU 프로세스가 실시간으로 가로채 호스트 CPU가 알아듣는 명령어로 번역(translation)해 실행한다. 이 동적 번역 엔진을 TCG(Tiny Code Generator)라 부른다.
▶ 중점 영역: 하드웨어에 종속되지 않는 소프트웨어적 유연성. x86 PC 위에서 ARM용 OS를 돌리거나, 단종된 옛 시스템을 부활시키는 교차 아키텍처(cross-architecture)가 가능하다.
▶ 속도: 모든 명령어를 번역하므로 오버헤드가 크다. Linaro·arXiv 자료에 따르면 QEMU TCG 순수 에뮬레이션은 동적 이진 변환과 중간표현(IR) 파이프라인 처리 비용 때문에 네이티브 대비 통상 10배 이상 느리다(출처: Linaro.org, arXiv.org, 검색일 2026-06-24).
KVM — 하드웨어 중심 가상화
KVM(Kernel-based Virtual Machine)은 리눅스 커널 자체를 하이퍼바이저로 바꿔 주는 커널 모듈이다. 명령어 번역을 하지 않는다. 대신 인텔 VT-x, AMD AMD-V처럼 현대 CPU에 물리적으로 내장된 하드웨어 가상화 확장 기능을 직접 활용해, 게스트의 연산 명령을 실제 물리 CPU로 직행시킨다(direct execution).
▶ 중점 영역: 하드웨어 가속을 이용한 성능 최적화. 단, KVM은 철저히 CPU와 메모리 가상화에만 집중한다.
▶ 속도: 중간 번역이 없어 네이티브에 근접한다. 다만 오버헤드가 0은 아니다. 연산 위주 작업은 약 3~5%, 디스크 I/O는 가상화 스택을 거치며 약 10~15% 오버헤드가 보고된다(출처: pextra.cloud, commandlinux.com, 검색일 2026-06-24).
여기서 흔히 깔리는 가정 하나를 짚는다. “KVM은 네이티브와 똑같다“는 말은 정확하지 않다. CPU 연산은 거의 동일하지만 I/O 경로에는 두 자릿수 % 오버헤드가 남는다. 그래서 뒤에서 설명할 반가상화(virtio)가 등장한다. 아래는 같은 작업을 네이티브로 돌렸을 때를 100%로 두고, 세 방식의 실행 속도를 나란히 비교한 것이다.
한눈에 보는 비교표
| 구분 | QEMU (에뮬레이터) | KVM (가상화 모듈) |
|---|---|---|
| 설계 사상 | 소프트웨어 명령어 번역(TCG) | 하드웨어 기능 기반 직접 실행 |
| 중점 | 소프트웨어 유연성(장치·아키텍처 모사) | 하드웨어 성능(CPU·메모리) |
| 속도 | 느림 (네이티브 대비 10배+ 저하) | 매우 빠름 (CPU 3~5%, I/O 10~15% 오버헤드) |
| 아키텍처 교차 | 가능 (x86에서 ARM 실행) | 불가 (호스트=게스트 아키텍처) |
| 주변기기 | 디스크·네트워크·USB 완벽 모사 | 담당 안 함 (CPU·메모리만) |
🔗 왜 둘을 합치는가 — QEMU-KVM 아키텍처
KVM 단독으로는 완전한 컴퓨터를 만들 수 없다. CPU·메모리는 처리해도 디스크 컨트롤러나 네트워크 카드 같은 주변기기가 없어 OS 부팅조차 못 한다. 반대로 QEMU 단독은 주변기기는 풍부하나 너무 느려 상용 서버에 못 쓴다. 그래서 현대 리눅스 생태계는 둘의 장점만 합친 QEMU-KVM 구조를 표준으로 채택했다. 이는 보안을 위해 커널 영역(kernel space)과 사용자 영역(user space)을 분리하는 컴퓨터 과학의 기본 원칙과도 정확히 맞물린다.
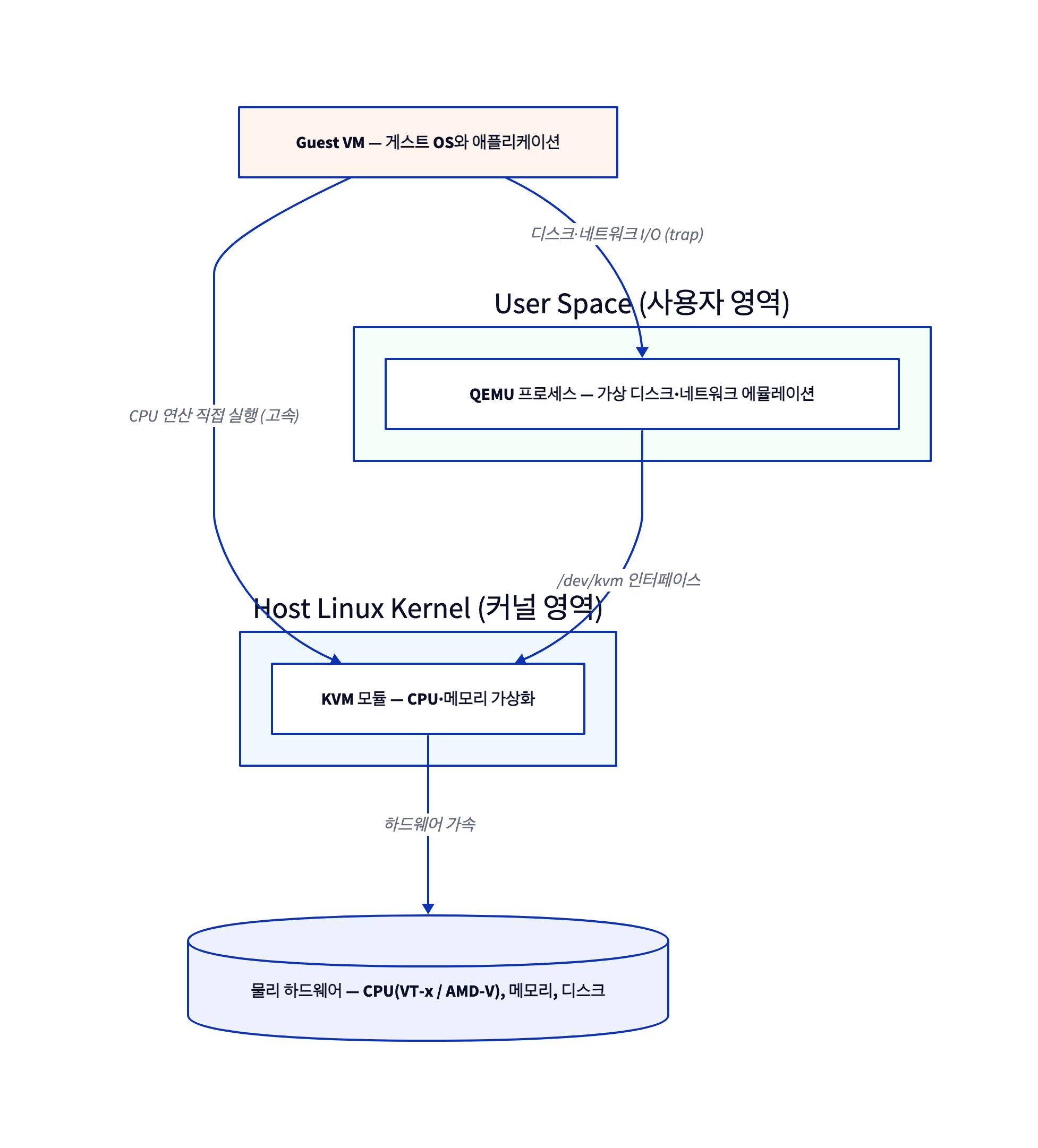
🔗 다이어그램 요약: 게스트의 CPU 연산은 커널의 KVM 모듈을 통해 물리 하드웨어로 곧장 직행해 빠르게 처리되고, 디스크·네트워크 같은 I/O 요청만 사용자 영역의 QEMU 프로세스로 빠져 소프트웨어로 모사된다. QEMU는 `/dev/kvm` 인터페이스로 커널의 KVM과 연결된다.
업무 분담은 이렇게 일어난다.
1️⃣ 순수 연산 — 게스트가 DB를 검색하거나 복잡한 수식을 계산하는 작업은 KVM을 타고 물리 CPU로 직행해 지연 없이 처리된다.
2️⃣ I/O — 게스트가 가상 디스크에 파일을 저장하려 하면 CPU 실행이 일시 중단(trap)되고 제어권이 QEMU로 넘어간다. QEMU는 소프트웨어로 모사한 가상 디스크 컨트롤러를 통해 데이터를 호스트 스토리지 파일에 기록한다.
시간선: 하드웨어 가상화가 판도를 바꾸다
하드웨어 가상화 확장은 비교적 최근 기술이다. Intel VT-x는 2005년, AMD-V(코드명 Pacifica)는 2006년에 도입됐다(출처: Wikipedia “x86 virtualization”, PCMag, 검색일 2026-06-24). 이 하드웨어 지원이 보급되면서 가상화는 “느려서 못 쓰는 것”에서 “네이티브급”으로 단숨에 전환됐다.
반가상화(virtio)로 I/O 병목 뚫기
I/O 오버헤드를 줄이기 위한 보강책이 virtio(반가상화) 장치다. 진짜 하드웨어를 흉내 내는 대신 “가상 환경임을 게스트가 인지”하고 효율적 인터페이스로 직접 통신한다. vhost-net 같은 백엔드와 다중 큐를 쓰면 virtio-net은 호스트 CPU와 물리 NIC 성능에 따라 10Gbps·40Gbps 링크를 쉽게 포화시키며, vhost-user와 DPDK를 결합하면 최대 100Gbps까지 도달한다(출처: DPDK.org, Linux-KVM.org, 검색일 2026-06-24).
🧰 사용 목적과 대표 예시
① 엔터프라이즈 클라우드 인프라 (QEMU-KVM 결합)
목적: 프라이빗/퍼블릭 클라우드(IaaS) 구축.
예시: OpenStack, Proxmox VE가 백엔드에서 QEMU-KVM을 호출해 VM 인스턴스를 생성한다. 관리자는 libvirt 도구로 수백~수천 대의 VM을 중앙에서 통제한다.
② 크로스 컴파일·펌웨어 테스트 (QEMU 단독)
목적: 개발 PC와 타깃 기기의 CPU 아키텍처가 다를 때의 사전 검증.
예시: x86 PC 위에서 QEMU로 가상 ARM 환경을 띄워 공유기·IoT용 ARM 리눅스 커널을 테스트한다. 속도보다 논리적 동작의 정확성 검증이 목적이다.
③ 모바일 앱 에뮬레이터
목적: PC에서 모바일 앱의 UI·동작 통합 테스트.
예시: 안드로이드 스튜디오의 가상 기기(AVD)는 내부적으로 QEMU 기반이다. 과거엔 순수 TCG 번역이라 느렸으나, 오늘날은 리눅스의 KVM이나 윈도우의 WHPX/HAXM 하이퍼바이저와 연동해 실기에 맞먹는 속도를 낸다.
🎯 정리: 유연한 설계자와 빠른 엔진
🧠 QEMU는 어떤 형태의 하드웨어든 소프트웨어로 창조해 내는 ‘유연한 설계자’이고, KVM은 CPU의 하드웨어 가상화 기능을 끌어내 가상 머신의 심장을 네이티브급으로 뛰게 하는 ‘엔진’이다.
QEMU 단독은 유연하나 느리고(네이티브 대비 10배+), KVM 단독은 빠르나 주변기기가 없다. 그래서 현대 리눅스 가상화는 QEMU-KVM 결합에 virtio 보강을 더한 형태로 수렴했고, 2005~2006년 Intel VT-x·AMD-V의 등장이 그 결합을 실용 단계로 끌어올린 전환점이었다. 우리가 매일 쓰는 전 세계 클라우드 컴퓨팅은 바로 이 정교한 분업 아키텍처 위에 세워져 있다. 클라우드 인스턴스를 하나 띄우는 단순한 클릭 뒤에는, ‘연산은 직행시키고 입출력만 우회시킨다’는 두 기술의 절묘한 협업이 매 순간 작동하고 있는 셈이다.
📚 참고 자료: Linaro.org, arXiv.org(QEMU TCG 성능), pextra.cloud·commandlinux.com(KVM 오버헤드), Wikipedia “x86 virtualization”·PCMag(VT-x/AMD-V 도입 시점), DPDK.org·Linux-KVM.org(virtio 처리량). 검색일 2026-06-24.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-24