⚡ 같은 SRAM인데 OD는 통과, NM은 실패 — 그 전압의 비밀
SoC 메모리 서명(Signoff) 실무에서 가장 자주 마주치는 타이밍 미스터리를 소자 물리부터 코너 검증까지 세 층위로 풀어봅니다.
같은 크기, 같은 목표 주파수로 메모리 컴파일러에 PVT를 넣었는데 OD(Over-Drive) 모드에서는 타이밍을 통과하지만 NM(Nominal) 모드에서는 같은 주파수를 못 맞추는 경험, 칩 설계자라면 한 번쯤 겪습니다. 결론부터 말하면 트랜지스터의 속도가 전압에 선형이 아니라 비선형으로 반응하기 때문입니다. 핵심 변수는 공급 전압(VDD)이 트랜지스터의 구동 전류와 접근 시간(Access Time)에 비선형적으로 작용한다는 점이며, 이를 ① 소자 물리·딜레이 모델, ② SRAM 특화 센싱 한계, ③ 파운드리 코너 서명 방법론의 세 층위로 분해해 설명합니다.
🔋 먼저 알아둘 것: 전압 모드와 PVT의 의미
메모리 컴파일러에 입력하는 PVT는 Process(공정)·Voltage(전압)·Temperature(온도)의 변동성을 의미합니다. 칩이 모든 극한 환경에서 동작함을 보장하기 위한 코너(Corner) 검증 좌표인데, 질문의 UD/NM/OD는 이 가운데 전압 축에 해당합니다. 같은 칩이라도 공장 출하 편차, 배터리 잔량, 발열 상태에 따라 실제 동작 조건이 달라지므로, 가장 가혹한 좌표에서도 깨지지 않아야 양산이 가능합니다.
| 전압 모드 | 전압 수준 | 특성 |
|---|---|---|
| OD (Over-Drive) | 표준보다 높음 | 구동력 극대화 → 최고속, 단 전력·발열·노화 증가 |
| NM (Nominal) | 표준 전압 | 전력-성능 균형 |
| UD (Under-Drive) | 표준보다 낮음 | 누설·동적 전력 최소화, 속도 최저 |
여기서 중요한 출발점 하나. SRAM의 ‘크기(Size)’가 커진다는 건 6T 셀(트랜지스터 6개로 1비트 저장)의 행(Row)과 열(Column)이 늘어나 워드라인(Wordline)·비트라인(Bitline)의 물리적 길이가 길어짐을 뜻합니다. 배선이 길어지면 그만큼 신호 경로의 기생 정전용량(Cload, 충·방전해야 할 전기 용량)이 커집니다. 마치 짧은 빨대보다 긴 빨대가 비우는 데 더 오래 걸리는 것과 같습니다. 이 늘어난 부하가 이후 모든 분석의 뿌리입니다.
📉 원인 ① 사쿠라이 알파-파워 법칙 — 전압이 낮아지면 딜레이가 ‘폭발’한다
가장 근본적인 학술적 근거는 사쿠라이 알파-파워 법칙(Sakurai Alpha-Power Law Delay Model)입니다. 이 모델은 미세 공정 MOSFET의 속도 포화(Velocity Saturation, 전압을 더 올려도 캐리어 속도가 더는 빨라지지 않는 현상)를 반영해 회로 딜레이를 다음처럼 정의합니다.
출처: T. Sakurai and A. R. Newton, “Alpha-power law MOSFET model and its applications to CMOS inverter delay and other formulas,” IEEE Journal of Solid-State Circuits, vol. 25, no. 2, pp. 584–594, April 1990.
이 식 하나가 OD→NM 현상의 핵심을 설명합니다.
🟢 OD 모드: (VDD − VTH) 항이 충분히 커서 구동 전류가 확보됩니다. 거대한 Cload를 가진 비트라인도 목표 클럭 주기 안에 방전되어 Access Time을 만족합니다.
🔴 NM 모드: VDD가 낮아지면 분모의 (VDD − VTH)α 항이 급격히 축소됩니다. 분자의 VDD 감소(선형)보다 분모 항의 감소가 더 가팔라서, 셀 트랜지스터의 구동력이 급감하고 딜레이 td가 비선형적으로 팽창합니다.
즉, 전압을 NM으로 낮추면 딜레이가 비례적으로(선형) 늘어나는 게 아니라 지수적으로 폭발합니다. 아래 그래프가 그 모양을 그대로 보여줍니다 — 전압이 OD에서 NM 쪽으로 내려갈수록 딜레이 곡선이 완만하지 않고 가파르게 치솟아, 타겟 클럭 주기 선을 NM 지점에서 넘어섭니다.
같은 메커니즘을 1차 근사식 Tdelay ∝ Cload × VDD / Iavg로 봐도 결론은 같습니다. 메모리가 클수록 Cload가 커지므로 이 거대한 부하를 시간 안에 충·방전하려면 막대한 평균 전류(Iavg)가 필요하고, 그 전류는 오직 높은 VDD, 즉 OD에서만 확보됩니다.
🔍 원인 ② SRAM만의 병목 — 센스 앰프 오프셋과 비트라인 방전
SRAM은 일반 로직과 다릅니다. 읽기 동작이 미세한 차동 전압을 증폭하는 아날로그 과정이라는 특수성이 있습니다. 여기서 저전압이 가장 치명적으로 작용하는 지점이 데이터를 읽어내는 센스 앰프(Sense Amplifier)의 입력 환산 오프셋 전압(VOS)입니다.
읽기가 성공하려면 비트라인 전위차 ΔVBL이 센스 앰프 고유의 오프셋 VOS를 넘어서야 합니다.
문제는 공정이 미세화될수록 VOS의 표준편차(σOS)가 구조적으로 커진다는 점입니다. NM으로 전압을 낮추면 셀 구동력이 약해져 충분한 ΔVBL을 만드는 데 걸리는 시간이 길어지고, 설계자는 오프셋 마진을 확보하려고 SAE(Sense Amp Enable) 신호를 더 늦게 켤 수밖에 없습니다. 이 지연이 Access Time을 직접 늘려 고주파 동작을 막는 핵심 원인이 됩니다.
반대로 OD에서는 셀 내부의 풀다운(Pull-down)·패스게이트(Pass-gate) 트랜지스터의 전류 구동력이 강해져 비트라인 방전 속도(Discharge Rate)가 기하급수적으로 빨라집니다. 그만큼 센스 앰프를 켜도 되는 시점이 앞당겨지죠. 결국 저전압에서는 “방전이 느려짐 + 오프셋 마진 확보를 위한 SAE 지연”이라는 이중 페널티가 겹쳐서 부과됩니다.
🏭 원인 ③ 파운드리 코너 서명 — 가장 느린 좌표에서 증명해야 한다
세 번째 층위는 컴파일러가 Pass/Fail을 판정하는 서명 코너(Signoff Corner) 자체에 있습니다. TSMC·삼성 같은 파운드리의 SRAM 컴파일러는 MMMC(Multi-Mode Multi-Corner) 기준으로 데이터시트의 Access Time을 산출합니다. 즉 전압 모드(OD/NM/UD)와 공정 코너(SSG / TT / FF)를 격자처럼 교차시켜 검증합니다.
SRAM이 목표 주파수를 ‘보장’받으려면 셋업 타이밍을 결정하는 가장 느린 코너(SSG, Slow-Slow Global) + 낮은 전압 모드에서 Access Time을 통과해야 합니다. 아래 매트릭스가 그 결과를 한눈에 보여줍니다 — 통과(녹색)는 빠른 코너·높은 전압에 몰려 있고, Fail(적색)은 느린 코너·낮은 전압 구석에 집중됩니다.
| 전압 모드 \ 공정 코너 | SSG (느림) | TT (전형) | FF (빠름) |
|---|---|---|---|
| OD | 통과 | 통과 | 통과 |
| NM | Fail | 통과(빠듯) | 통과 |
| UD | Fail | Fail | 통과(빠듯) |
정리하면, OD 모드는 구동력이 넘쳐 SSG 코너에서도 Access Time이 짧아 통과합니다. 반면 NM 모드는 SSG 코너와 결합될 때 ①의 알파-파워 딜레이 팽창과 ②의 VOS 타이밍 페널티가 중첩되어 Access Time이 타겟 클럭 주기를 초과합니다. 사용자가 본 Fail 메시지는 단일 원인이 아니라 “느린 공정 코너 × 낮은 전압 × SRAM 센싱 한계”의 합산 결과일 가능성이 높습니다.
참고로 이 세 가지 원인은 서로 충돌하지 않습니다. 소자 물리·회로 딜레이 관점에서 본 설명과, 사쿠라이 모델·센스 앰프 오프셋·코너 서명 관점에서 본 설명은 같은 결론을 서로 다른 깊이에서 보강하는 상호 보완 관계입니다. 어느 각도에서 들여다봐도 “저전압에서 딜레이가 비선형으로 늘어 타이밍을 못 맞춘다”는 결론으로 수렴합니다. 그 수렴 구조를 다이어그램으로 옮기면 다음과 같습니다.
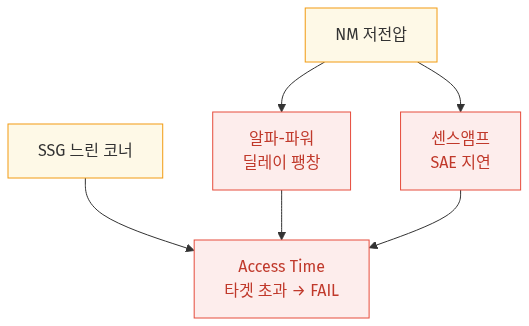
🔗 다이어그램 요약: NM 저전압이 ‘딜레이 팽창’과 ‘센스 앰프 SAE 지연’ 두 갈래로 작용하고, 여기에 SSG 느린 공정 코너가 더해지면서 Access Time이 타겟 클럭 주기를 넘어 최종적으로 FAIL로 수렴합니다.
💸 OD로 주파수를 맞추면 치르는 대가
“그냥 OD 쓰면 되잖아?”라고 생각하기 쉽지만, OD 채택은 시스템 전반에 비용을 전가합니다.
🔴 동적 전력의 제곱 증가
전압의 제곱에 비례하므로 NM→OD 상승은 전력을 가파르게 끌어올립니다. 누설 전류(정적 전력)도 전압에 지수적으로 증가합니다.
전압을 1.0배(NM)에서 1.2배(OD)로 20% 올리면 동적 전력은 약 1.44배로, 즉 44%나 뛰어오릅니다. 반대로 UD(0.8배)로 내리면 0.64배까지 떨어지죠. 전압 한 단계의 무게를 막대 길이로 비교하면 다음과 같습니다(NM = 1.0배 기준).
🔴 신뢰성·수명 단축: OD의 높은 전압이 게이트 산화막에 지속 인가되면 NBTI(Negative Bias Temperature Instability)·HCI(Hot Carrier Injection) 같은 노화가 가속됩니다. 장기적으로 Vth가 상승해 다시 속도가 느려지는 악순환을 부릅니다.
🔴 물리 설계 복잡성: SRAM만 OD 전압을 요구하면 별도 전원 도메인, 레벨 시프터, 추가 LDO/PMIC가 필요해 면적과 설계 난이도가 올라갑니다.
🛠️ OD를 올리기 전, 먼저 검토할 대안
전력·수명 페널티가 크므로 무작정 OD를 채택하기 전에 아키텍처·라이브러리 차원의 대안을 먼저 검토하는 것이 정석입니다.
✅ 메모리 뱅킹/파티셔닝(Banking/Partitioning): 하나의 거대한 블록 대신 작은 블록 여러 개로 분할 → 워드라인·비트라인이 짧아져 Cload 감소 → NM에서도 타겟 주파수 달성 확률 상승. 가장 먼저 시도할 만한 카드입니다.
✅ LVT/ULVT 셀 활용: 낮은 Vth 옵션으로 컴파일하면 (VDD − VTH) 항이 커져 NM 전압에서도 구동 전류를 확보할 수 있습니다(단, 누설 증가 트레이드오프 고려).
✅ 파이프라이닝(Pipelining): 메모리 접근을 2사이클 이상으로 분할해 사이클당 타이밍 마진을 늘리면 NM에서도 안정 동작이 가능합니다.
의사결정 순서를 간단히 그리면 다음과 같습니다 — 먼저 아키텍처·라이브러리 대안으로 풀리는지 보고, 끝내 안 되면 그때 비로소 OD를 최후 수단으로 올립니다.
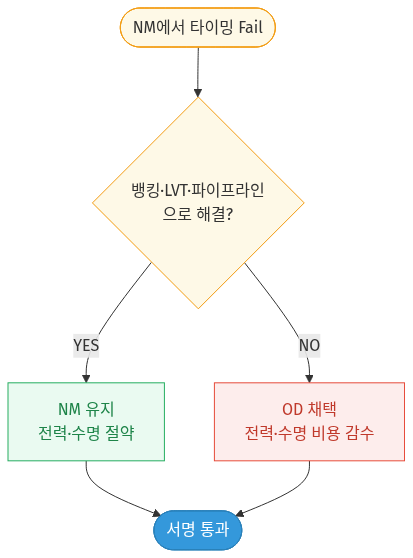
🔁 다이어그램 요약: NM 타이밍 실패 시 먼저 뱅킹·LVT 셀·파이프라이닝으로 해결되는지 확인 — 해결되면 NM을 유지해 전력·수명을 아끼고, 끝내 안 되면 전력·수명 비용을 감수하고 OD를 최후 수단으로 채택합니다.
🧠 한 문장으로 남기는 핵심
“OD에서 통과한 메모리가 NM에서 실패하는 이유는 트랜지스터 특성이 선형이 아니기 때문이다. ① 사쿠라이 알파-파워 법칙에 따른 전압 감소 시 지수적 딜레이 팽창, ② 센스 앰프 오프셋 마진 확보를 위한 필연적 SAE 타이밍 지연, ③ 파운드리가 보증해야 하는 최악 공정 코너(SSG)와의 중첩이 복합적으로 작용한 결과다. 메모리 크기가 클수록 Cload가 커져 이 효과는 더 두드러진다.”
설계자의 자세로 옮기면 단순합니다. 타이밍이 안 맞을 때 가장 손쉬워 보이는 OD는 사실 가장 비싼 선택입니다. 먼저 메모리를 잘게 쪼개고(뱅킹), 빠른 셀(LVT)을 고르고, 접근을 나누어(파이프라인) 본 다음, 그래도 안 될 때 마지막으로 전압을 올리는 것 — 이 순서가 전력·수명·면적을 모두 지키는 길입니다.
📚 참고 자료
▶ Sakurai Alpha-Power Law MOSFET Model (IEEE JSSC, 1990)
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-13