GLM-5.2 도입 가이드 — 비용·성능·하드웨어·보안을 4축으로 정리하다
코딩과 에이전트 자동화에 특화된 오픈웨이트(open-weights) AI 모델 GLM-5.2가 프론티어 진영의 비용 구조를 흔들고 있다. 중국 Zhipu AI(글로벌 서비스명 Z.ai)가 2026년 6월 13일 공개한 이 모델은, 클로즈드 소스인 GPT-5.5(OpenAI)·Claude Opus 4.8(Anthropic)에 근접한 성능을 가중치를 직접 내려받아 사내망에서 돌릴 수 있는 형태로 제공한다는 점이 핵심이다. 이 글은 정체·성능·비용·하드웨어 사양·설치·보안을 순서대로 짚어, 실제 도입을 검토하는 입장에서 무엇을 따져야 하는지를 정리한다.
📅 기준 시점: 2026년 6월 · 카테고리: IT/AI 인프라
한눈에 보는 핵심 결론
▶ 출처: 중국 Zhipu AI(Z.ai). 2026-06-13 공개, Hugging Face 저장소 zai-org/GLM-5.2로 가중치 배포.
▶ 체급: 약 744B~753B 파라미터의 MoE(전문가 혼합) 모델, 토큰당 활성 파라미터 약 40B, 컨텍스트 100만(1M) 토큰.
▶ 성능: 프론티어급에 근접하나, 공개 벤치마크상 Opus 4.8을 일관되게 상회하지는 못한다.
▶ 비용: API 기준 입력 $1대·출력 $4대로, GPT-5.5·Opus 4.8 대비 약 5~7배 저렴.
▶ 사양: 개인 PC로는 구동 불가. 로컬은 사실상 엔터프라이즈 인프라(다중 H100/H200, 256GB+ Mac 통합메모리)가 전제.
▶ 보안: 모델 자체 웹서치 없음(함수 호출로 연동). 망분리 온프레미스 + 샌드박스 격리가 권장 구도.
GLM-5.2의 정체와 아키텍처
GLM-5.2는 단순 챗봇이 아니라 수백 개 파일 규모의 코드베이스를 한 번에 읽고, 여러 단계를 거치는 장기 워크플로우(long-horizon)를 스스로 수행하도록 설계된 에이전트 특화 모델이다. 구조적 특징은 세 가지로 압축된다.
▶ MoE (Mixture-of-Experts)
총 744B~753B 파라미터를 갖되, 토큰당 약 40B만 활성화해 연산량을 통제한다. 모델 전체는 거대하지만 한 번에 일하는 부분은 작아, 덩치 대비 효율이 높다.
▶ IndexShare (희소 주의)
4개 레이어마다 단일 인덱서를 재사용하는 희소 주의(sparse-attention) 기법으로, 토큰당 연산량(FLOPs)을 약 2.9배 줄인다. 긴 문맥을 다룰수록 비용 절감 효과가 커지는 구조다.
▶ MTP (Multi-Token Prediction)
한 번에 여러 토큰을 미리 예측해 처리 속도를 높이는 계층이다. 추론 깊이는 High / Max 두 모드 중에서 골라, 비용과 응답 지연(latency)을 상황에 맞게 조절할 수 있다.
🟡 라이선스는 직접 확인이 안전하다
공개 초기에는 라이선스 근거가 z.ai 홈페이지뿐이라 종류를 확정하기 어려웠다. 이후 Hugging Face 저장소(zai-org/GLM-5.2)와 서드파티(eigent.ai)가 지역 제한 없는 MIT License로 보고했다. 다만 정식 정적 Model Card(PDF) 대신 블로그·저장소 페이지로 공개된 만큼, 상업적 재배포처럼 민감한 용도라면 저장소의 LICENSE 파일 원문을 직접 확인하는 편을 권한다.
성능 벤치마크 — 어디서 앞서고 어디서 뒤지나
성능 평가는 자료에 따라 결이 갈린다. 한쪽에서는 GLM-5.2가 “GPT-5.5·Opus 4.8에 필적하거나 일부 상회”한다고 보지만, 실제 점수가 붙은 자료를 보면 그 ‘상회’ 주장은 일부 지표에서만 성립한다. 아래 표가 그 차이를 그대로 보여준다.
| 벤치마크 | Opus 4.8 | GLM-5.2 | GPT-5.5 |
|---|---|---|---|
| FrontierSWE 에이전트 코딩 |
75.1 | 74.4 | 72.6 |
| SWE-bench Pro 다중 파일 레포 문제 |
69.2 | 62.1 | 58.6 |
| Terminal-Bench 2.1 터미널 에이전트 |
미제시 | 81.0 | 미제시 |
특히 다중 파일을 다루는 SWE-bench Pro에서 격차가 분명하다. 막대 길이로 보면 한눈에 들어온다.
SWE-bench Pro 점수 비교 (높을수록 우수)
정리하면 이렇다. FrontierSWE는 Opus 4.8(75.1)과 GLM-5.2(74.4)가 1점 미만 차이로 사실상 동급이다. SWE-bench Pro는 Opus 4.8이 7점 이상 앞서 명확한 우위다. Terminal-Bench 2.1은 GLM-5.2가 81.0으로 전 버전 GLM-5.1(62.0)에서 크게 올랐지만, 같은 표에 경쟁 모델 점수가 없어 직접 비교는 불가하다.
따라서 “프론티어 근접·일부 동급”이 가장 정확한 표현이며, 위 세 지표만으로는 Opus 4.8을 전반적으로 능가한다고 보기는 어렵다. 또 점수 출처가 1차 모델 카드가 아니라 평가 매체·플랫폼인 만큼, 의사결정에 쓸 때는 자체 코드베이스 기준 사내 평가로 다시 확인하는 편이 안전하다.
비용 — API 기준 5~7배의 격차
GLM-5.2의 가장 두드러진 강점은 가격이다. 같은 1M(100만) 토큰을 처리할 때 드는 비용을 비교하면 차이가 분명하다.
| 모델 | 입력 (1M) | 출력 (1M) |
|---|---|---|
| GLM-5.2 | $1.00~$1.40 | $4.00~$4.40 |
| GPT-5.5 (Standard) | $5.00 | $30.00 |
| Claude Opus 4.8 | $5.00 | $25.00 |
※ GLM-5.2는 코딩 특화 월 구독(GLM Coding Plan) 약 $16.20/월 옵션도 있다. GPT-5.5 Pro는 $30/$180, Opus 4.8 Fast mode는 $10/$50 별도.
출력 토큰 단가 비교 (1M 토큰 · 낮을수록 저렴)
출력 토큰 기준 GPT-5.5 대비 약 7배, Opus 4.8 대비 약 6배 저렴하다. 토큰을 많이 쓰는 에이전트형 워크로드일수록 누적 절감 폭이 커진다. 다만 로컬 구축으로 가면 라이선스 비용은 0이 되는 대신 하드웨어 초기 투자가 API 절감분을 압도할 수 있으므로, 비용 비교는 반드시 사용량 규모·보안 요구와 함께 따져야 한다.
로컬 구동 하드웨어 — 엔터프라이즈 장비가 전제
744B라는 체급 때문에 개인용 PC에서는 어떤 방식으로도 전체 모델 구동이 불가능하며, 사실상 엔터프라이즈급 인프라가 전제된다. 아래 수치는 초기 아키텍처 추정(양자화 가정 포함)이라 변동 가능하나, 자릿수 감각은 신뢰할 만하다.
🖥️ Intel / AMD 기반 (NVIDIA GPU)
• 소비자 최상위 RTX 4090(24GB) 1대로는 전체 모델 적재 불가
• 최소 2-bit 구동: RTX 3090/4090 4장(~100GB VRAM) 다중 GPU 분산 추론
• 기업용 4-bit 구동: 약 370~500GB VRAM → H100(80GB) 6~8대 규모
• 프로덕션 권장: vLLM/SGLang 기준 8× H200 등 + 1M 컨텍스트용 KV 캐시 여유분
🍎 Mac (Apple Silicon)
• 2-bit 양자화(GGUF) 구동에 최소 256GB 통합 메모리(Unified Memory) 필요
• 즉 M3 Ultra 또는 M4 Ultra 칩 최상위 Mac Studio / Mac Pro에서만 제한적으로 가능
• 통합메모리라 RAM=VRAM으로 쓰는 이점은 있으나, 256GB는 최상위 구성에 해당
요약하면, “로컬 구동 가능 여부”의 답은 “예, 단 엔터프라이즈 장비 한정”이다. 일반 워크스테이션·게이밍 PC·보급형 Mac으로는 불가하다.
설치와 사용 — 추론 서버 + 에이전트 클라이언트 2계층
흔한 기대와 달리 GLM-5.2 로컬 활용은 명령어 한 줄로 끝나지 않는다. 모델을 실제로 돌리는 백엔드(추론 서버)와, 사람이 대화하며 일을 시키는 프론트엔드(에이전트 클라이언트)를 분리해 구성하는 2계층 구조다. 전체 그림은 다음과 같다.
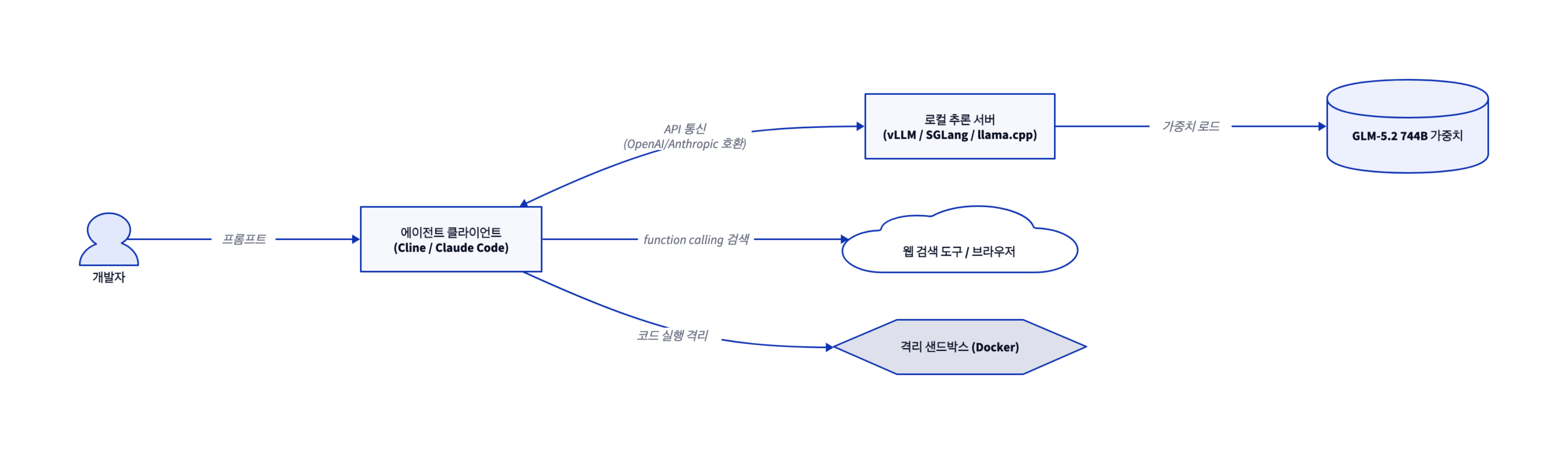
🔗 다이어그램 요약: 개발자의 프롬프트는 에이전트 클라이언트(Cline·Claude Code)로 들어가고, 클라이언트는 OpenAI/Anthropic 호환 API로 로컬 추론 서버(vLLM·SGLang)와 통신한다. 추론 서버가 744B 가중치를 적재해 모델을 돌리며, 웹 검색은 함수 호출로, 코드 실행은 Docker 샌드박스로 격리해 처리한다.
(1) 백엔드 — 터미널에서 pip 설치
대표적으로 vLLM 또는 SGLang을 추론 서버로 띄운다.
# vLLM
pip install -U vllm
vllm serve zai-org/GLM-5.2-FP8 \
--tensor-parallel-size 8 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice
# SGLang
pip install sglang
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.2" \
--host 0.0.0.0 --port 30000 \
--reasoning-parser glm45 \
--tool-call-parser glm47 --tp-size 8--tool-call-parser glm47 / --reasoning-parser glm45는 사고(thinking) 토큰과 도구 호출 토큰을 올바로 파싱하기 위한 필수 옵션이다. 빠뜨리면 추론·도구 호출이 깨진다.
(2) 프론트엔드 — 에이전트 툴 연동
서버형 API만 쓸 거라면 백엔드 없이 Z.ai의 Anthropic/OpenAI 호환 엔드포인트에 바로 붙이면 된다.
▶ Claude Code
~/.claude/settings.json에 ANTHROPIC_BASE_URL=https://api.z.ai/api/anthropic, ANTHROPIC_AUTH_TOKEN=<Z.ai 키>를 설정하고, 모델명에 glm-5.2[1m], CLAUDE_CODE_AUTO_COMPACT_WINDOW=1000000을 줘야 1M 창이 온전히 활성화된다.
▶ Cline (VS Code)
Provider=OpenAI Compatible, Base URL=https://api.z.ai/api/coding/paas/v4, Model ID=glm-5.2, Context Window=1000000. effort를 High/Max로 주면 깊은 추론 모드가 유도된다.
“터미널 설치냐, 별도 에이전트 툴이냐”의 답은 둘 다이다. 로컬은 터미널에서 추론 서버를 띄운 뒤, 별도의 에이전트 클라이언트를 설치해 엔드포인트만 로컬 또는 Z.ai 주소로 바꿔 연동한다.
보안 — 세이프가드·웹서치·도입 전 점검
비용·성능만큼 중요한 축이 보안이며, 여기서 GLM-5.2 고유의 고려사항이 갈린다.
세이프가드(가드레일)
Zhipu AI는 남용 방지용 가드레일을 내장했다. 그러나 가중치를 직접 받는 개방형 모델 특성상, 받은 측이 미세조정(파인튜닝)으로 안전장치를 약화시키거나 프롬프트 인젝션으로 우회할 여지가 클로즈드 모델보다 크다. 또한 서구권 모델 대비 독립적인 퍼블릭 보안 감사 사례가 상대적으로 적다. 즉 벤더의 안전장치를 그대로 믿기보다, 도입 측이 자체 가드(입출력 필터·권한 제한)를 덧대는 것을 전제로 봐야 한다.
웹서치 — 모델 자체에는 없다
모델에 웹 검색 기능은 내장돼 있지 않다. 검색은 에이전트 클라이언트의 함수 호출(function calling)로 동작한다. 모델이 “검색이 필요하다”고 판단하면 클라이언트에 요청을 보내고, 클라이언트가 결과를 가져와 문맥에 주입하는 방식이다. 따라서 “웹서치 지원 여부”의 답은 “모델 단독으로는 미지원, 에이전트 도구를 통해 가능”이다.
🔴 웹서치를 켤 때의 위험과 완화책
웹서치를 허용하면 외부의 오염된 텍스트·악성 스크립트가 문맥 창을 통해 유입될 수 있고, 자율성을 가진 에이전트가 이를 그대로 터미널 명령으로 실행할 위험이 있다(간접 프롬프트 인젝션). 완화책은 세 가지다.
1️⃣ 에이전트 작업 공간을 호스트와 분리된 샌드박스(Docker 컨테이너) 안에 격리
2️⃣ 파일·네트워크·명령 실행 권한 최소화
3️⃣ 자동 실행보다 휴먼-인-더-루프 승인 단계 유지
지정학·컴플라이언스
중국 기업 모델이라는 태생적 특성상 데이터 주권·국가정보법 등 컴플라이언스 요건을 고려해야 한다. 코드·데이터를 외부로 내보낼 수 없는 조직이라면, 초기 하드웨어 투자를 감수하더라도 망분리 온프레미스(로컬) 호스팅이 데이터 유출 리스크를 원천 차단하는 가장 확실한 선택이다. 반대로 보안 요구가 낮고 사용량이 가변적이라면 저렴한 API가 합리적이다.
결론과 도입 의사결정
GLM-5.2의 본질적 가치는 “프론티어급에 근접한 성능을, 5~7배 저렴한 가격과 완전한 자체 호스팅 권한으로 제공”한다는 점이다. 4축으로 압축하면 다음과 같다.
| 축 | 평가 |
|---|---|
| 💰 비용 | 압도적 우위. API 사용 시 GPT-5.5·Opus 4.8 대비 5~7배 저렴 |
| 📊 성능 | 프론티어 근접·일부 동급. 단 SWE-bench Pro 등에서는 Opus 4.8에 명확히 뒤짐 |
| 🖥️ 사양 | 로컬 구동 가능하나 엔터프라이즈 장비 한정(H100/H200 다중 GPU, 256GB+ Mac). 일반 PC 불가 |
| 🔒 보안 | 망분리 온프레미스 + 샌드박스가 권장 구도. 웹서치는 함수 호출로만 가능, 인젝션 격리 필수 |
그렇다면 어떤 조직에 어떤 선택이 맞을까. 의사결정 흐름을 단순화하면 다음과 같다.
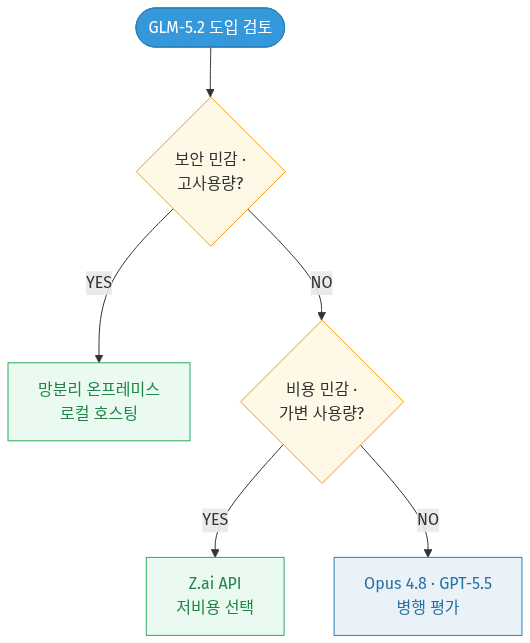
🔁 다이어그램 요약: 보안이 민감하고 사용량이 많은 조직은 망분리 온프레미스 로컬 호스팅으로 가고, 그렇지 않으면 비용 민감도를 본다. 비용·가변 사용량이 핵심이면 저렴한 Z.ai API가 답이고, 성능이 최우선이고 예산에 여유가 있다면 Opus 4.8·GPT-5.5를 병행 평가하는 쪽이 합리적이다.
🧠 어느 경로를 택하든, 도입 전 두 가지는 직접 검증하는 편이 안전하다. 벤치마크 점수는 사내 코드베이스 기준 자체 평가로, 라이선스 종류는 저장소 LICENSE 원문으로 재확인하는 것. 공개 자료는 빠르게 바뀌고 매체마다 결이 다르므로, 자기 환경에서의 실측이 가장 믿을 만한 근거다.
※ 본 글의 사양·가격·벤치마크 수치는 2026년 6월 공개 자료를 기준으로 정리한 것으로, 일부는 초기 추정치이며 이후 변동될 수 있다. 실제 도입·계약·투자 결정은 공식 저장소 문서와 자체 환경 검증을 거쳐 본인 책임 하에 판단할 것을 권한다.
본 글은 공개된 데이터와 출처를 바탕으로 작성했습니다. 최종 업데이트: 2026-06-22